Link: https://www.kaggle.com/c/child-mind-institute-detect-sleep-states
Problem Type: classification since we’re classifying each segment of time to see if someone is awake or not
Input: wrist accelerometer data
Output: the times when a user wakes up AND the times when a user sleeps
Eval Metric: Average Precision
- https://www.kaggle.com/code/metric/event-detection-ap/notebook
- note: from (1st)‘s solution, they say that:
- The competition’s evaluation metric doesn’t differentiate predictions within a 30-second range from the ground truth event.
- so your prediction has a margin of error of 30seconds and it’ll be correct
Summary
Detect sleep onset and wake from wrist-worn accelerometer data
Note: if you submitted multiple predictions for the same sleep event, you’ll get the same score (or better)
- https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states/discussion/460516
- competitors abused this bias to get a better score
Solutions
-
(1st) - very smart postprocsessing to make fuzzy predictions precise
- https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states/discussion/459715
- solution code: https://github.com/sakami0000/child-mind-institute-detect-sleep-states-1st-place
-
was based on this public notebook:
- https://www.kaggle.com/code/danielphalen/cmss-grunet-train
- KLDivergenceLoss was good because
-
- The target is “easily interpretable as a probability distribution”
-
- Ensembles are also easy to interpret, no matter how differently they are trained.
- HOWEVER, he switched to BCEWithLogitsLoss
-
- how to improve this notebook:
-
- use fastparquet
-
- add skip connections
-
- the autoencoder had a size of 1040. how did it compressed the time?
- SleepDatasetTrain preps the data
gap = 6*60*12 tmp = self.events[(self.events.series_id == series_id) & (self.events.night >= start) & (self.events.night <= end)] data = data[(data.step > (tmp.step.min() - gap)) & (data.step < (tmp.step.max() + gap))]
- SleepDatasetTrain preps the data
- KLDivergenceLoss was good because
- https://www.kaggle.com/code/danielphalen/cmss-grunet-train
-
For input scaling, SEModule was utilized. (https://arxiv.org/abs/1709.01507)
- SEModules
- Squeeze-and-Excitation block explained | by Taha Samavati | Medium
- basically: when we do a regular convolution, we apply the weights in the same way to all channels.
- SE block is similar, but the importance of each channel is individually assessed based on its context
- so it probably changes the kernel when doing the convolutions on a per-channel basis
- SE block is similar, but the importance of each channel is individually assessed based on its context
- SEModules
-
As noted in several discussions and notebooks, there was a bias in the minute when ground truth events occurred.
-
A decaying target is created based on the distance from the ground truth event, with diminishing values as the distance increases.
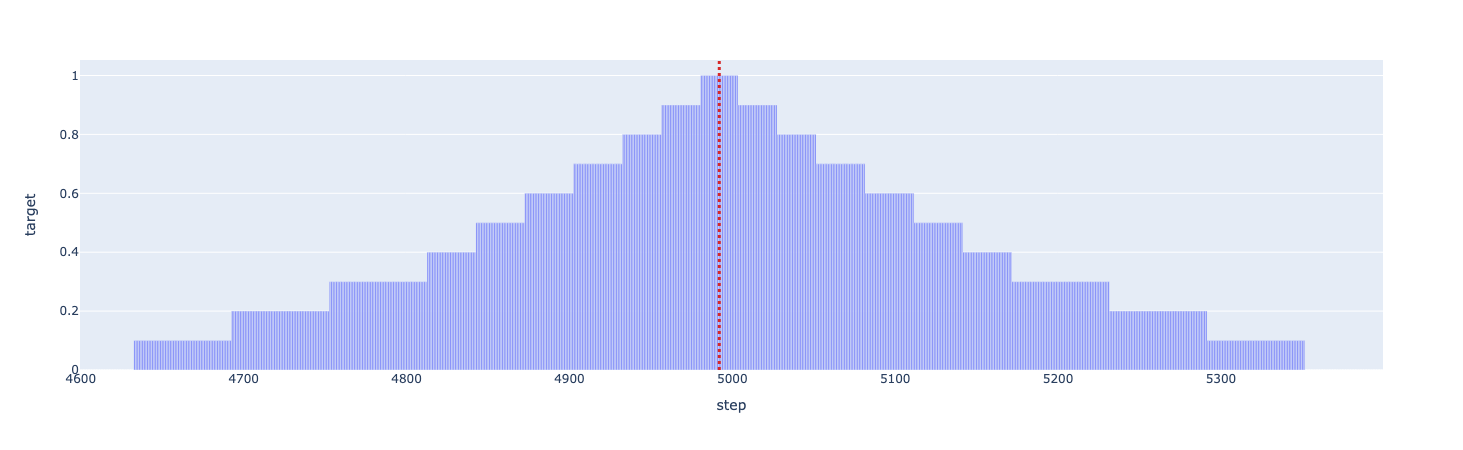
- every epoch, he decays the target:
targets = np.where(targets == 1.0, 1.0, (targets - (1.0 / config.n_epochs)).clip(min=0.0))- this sharpens the peaks for detecting onsets / wakeups
-
Missing data exists when the device is removed: https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states/discussion/459715
- when that happens, they use rules to predict the events
-
Their post-processing improved their score by a lot
-
- understand that with this metric, if your prediction is within 30 seconds of a ground truth event, you get full points
-
- use two models:
- model 1: every 5 seconds (the period of one time step), predict the probability of an onset / awake
- model 2: only predict 1 if you think they woke up on that second. Otherwise, predict 0
- This predicts a binary flag indicating whether the ground truth event exists at the point.
- They now use a greedy algorithm to find the points where the sum of the scores of its neighbours are the best
- If they already “used up” score from one window, they cannot reuse it for another
- “The reason we are only calculating for two points within a minute is to reduce computational complexity.”
- “In our case, performance did not improve with post-processing alone. (w/o daily normalization of the score)
- “The 2nd level model and daily normalization of the score were crucial elements in improving performance.”
-
-
- https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states/discussion/441470
- pure heuristic approach (HDCZA) ^g8mptz
- notebook: https://www.kaggle.com/code/tatamikenn/sleep-hdcza-a-pure-heuristic-approach-lb-0-447?scriptVersionId=149818796
- “Since ~37% of nights in training sequences has no sleep logs, I believe training model of predicting existence of sleep logs in the target night will get higher score in LB.”
- it was based on this paper: https://www.nature.com/articles/s41598-018-31266-z#data-availability
- the implementation details start at the “Accelerometer data preparation” section
- Heuristic algorithm looking at Distribution of Change in Z-Angle (HDCZA)
- Main steps of the heuristic (to find the SPT-window (The Sleep Period Time window)):
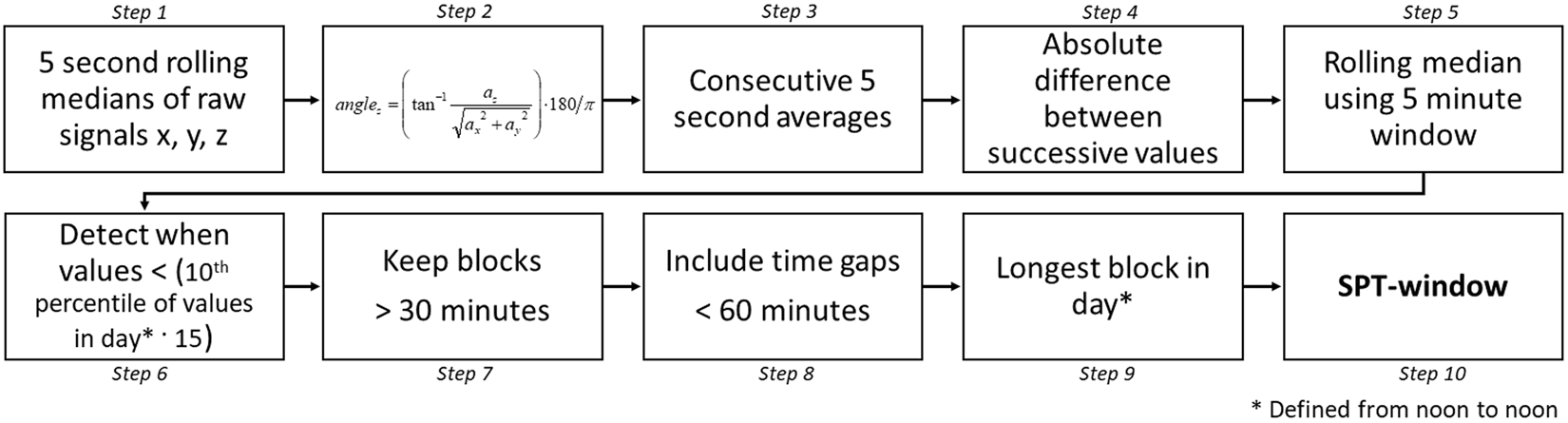
- angleZ seems like an important feature!
-
(2nd) - Two stage predictions: use LGBM to sharpen results from the first model (rather than smart postprocessing)
- https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states/discussion/459627
- used enssembling similar to Weighted Boxes Fusion (WBF) ensembling
- code
# ensemble after 2nd stage def weighted_fusion_ensemble(df_0, df_1, distance_threshold=100): weight_wo_fusion = 0.5 large_val = 1e8 series_ids = df_0['series_id'].unique() out_df = [] for series_id in series_ids: df_0_id = df_0[df_0['series_id']==series_id].copy() df_1_id = df_1[df_1['series_id']==series_id].copy() df_0_id = df_0_id.sort_values("score", ascending=False).reset_index(drop=True) df_1_id = df_1_id.sort_values("score", ascending=False).reset_index(drop=True) steps_0 = df_0_id['step'].values.copy() # base steps_1 = df_1_id['step'].values.copy() scores_0 = df_0_id['score'].values.copy() # base scores_1 = df_1_id['score'].values.copy() not_assigned_df = [] for step, score in zip(steps_1, scores_1): dists = np.abs(steps_0 - step) argmin = np.argmin(dists) min_dist = dists[argmin] if min_dist < distance_threshold: f_step = steps_0[argmin] f_score = scores_0[argmin] add_step = step add_score = score # new_score = (f_score + add_score) / 2 new_score = (f_score * f_score + add_score * add_score) / (f_score + add_score) new_step = (f_step * f_score + add_step * add_score) / (f_score + add_score) df_0_id.loc[argmin, "score"] = new_score df_0_id.loc[argmin, "step"] = new_step steps_0[argmin] = large_val # large val to avoid assign again else: not_assigned = df_1_id[df_1_id['step']==step].copy() not_assigned['score'] = score * weight_wo_fusion # not assigned not_assigned_df.append(not_assigned) df_0_id.loc[steps_0!=large_val, "score"] *= weight_wo_fusion # not assigned out_df.append(df_0_id) if len(not_assigned_df) >0: not_assigned_df = pd.concat(not_assigned_df) out_df.append(not_assigned_df) out_df = pd.concat(out_df).reset_index(drop=True) # .reset_index() # .rename(columns={"index": "row_id"}) return out_df
- code
- After getting the score for each step, he uses a LGBM model to predict the scores for the steps (but the steps are shifted by a bit)
- this is so he can get more predictions that are nearby. the extra predictions won’t harm his score
- he concats these new predictions back onto the original table from step 2
-
(3rd) - reduce granularity from 5sec to 30sec (most efficient solution). remove noise
- https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states/discussion/459599
- We decided to divide the series into one-day sequences and reduce the granularity from 5 secs to 30 secs
- probably to reduce model size and speed it up. They due have a 60-sec leeway with the eval metric
- feature engineering
- code: https://github.com/FNoaGut/child-mind-institute-detect-sleep-states-3rd-place-solution/blob/main/inference.py
- only had 3 features. Any more features was innacurate
- Made anglez absolute, giving +0.002 on local validation.
- For the only two variables we had (anglez and enmo), we tried to find useful aggregations(diff, mean, median, skew, etc…), but the only thing that seemed to work was the standard deviation (anglez_abs_std and enmo_std).
- Detecting noise: We realized that when exactly the same value is repeated in the same series at the same hour, minute and second, this was basically noise (user wasn’t wearing watch).
- once they detect noise, they will remove those nights:
- https://github.com/FNoaGut/child-mind-institute-detect-sleep-states-3rd-place-solution/blob/6c8a4d5aa6bea636db602927c27dfd91b8324798/preprocessing/preprocess.py#L396C8-L396C32
- This was how they calculated the noise removal cols: https://github.com/FNoaGut/child-mind-institute-detect-sleep-states-3rd-place-solution/blob/6c8a4d5aa6bea636db602927c27dfd91b8324798/inference.py#L221-L224
- To incorporate temporal information into the model, we decided to add 2 frequency encoding variables (one for onsets and one for wakeups) at the hour-minute level.
- Training their models
- Note: the model had to predict 2 targets (one for onsets and other for wakeups)
- Target transformation: Add two steps back and one forward. (0,0,0,0,1,0,0,0 → 0,0,1,1,1,1,0,0)
- prob cause just predicting on one time step is very hard
- loss : cross-entropy loss
- A good augmentation trick was to reverse all the series during training, this allowed us to have more sequences and increased our local validation by 0.01
- code
if ADD_INVERT_SERIES and MODE=='train': # ADD INVERT SERIES num_array_flip = np.flip(num_array_, axis=1).copy() target_array_flip = np.flip(np.flip(target_array_, axis=1), axis=2) mask_array_flip = np.flip(mask_array_, axis=1) pred_use_array_flip = np.flip(pred_use_array_, axis=1) num_array.append(num_array_flip) target_array.append(target_array_flip) mask_array.append(mask_array_flip) pred_use_array.append(pred_use_array_flip) time_array.append(time_array_) id_list.append(id_array_)- They flipped on axis=1. probably cause axis=0 is for each training instance
- Ok. I guess this is an ok thing to do since they are NOT extrapolating the future, they are merely identifying onset/wakeup times, so it’s good for the model to see data points in reverse time.
- important considerations:
- used Rolling_mean(center=True) to smooth the predictions
- Take the highest predictions every certain distance (this allows us to eliminate false positives)
- I COULDN’T find this logic in the github (at a glance)
- We decided to create sequences of days starting at 17:00 local time. If one day it was not complete at the beginning or at the end, we added padding.
- the final weighing of the models (in the ensemble) was adjusted manually based on local CV
-
(4th) - smart feature engineering. input dim: 17280 x n_features. output dim: 17280 x 2
- https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states/discussion/459637
- solution code: https://github.com/nikhilmishradevelop/kaggle-child-mind-institute-detect-sleep-states
- Model Inputs: 17280 x n_features length sequences as input (17280 = 12 steps_per_minute x 60_minutes * 24 hours)
- Model Outputs: 17280 x 2 (one for onset and other for wakeup)
- Model Type: Regression Model
- sequences with length < 17280 were padded to make them equal to 17280
- features:
- Original Sequence Features: Enmo, Anglez
- TimeStamp Features: Hour and Weekday
- Derived Sequence Features: Anglez difference, Enmo Difference, HDCZA features etc)
- explaining HDCZA
Transclude of Child-Mind-Institute---Detect-Sleep-States#^g8mptz
- TODO: penguin’s solution had many good features
- They actually used WBF in their ensemble
- Final_Sub = WBF(Penguins_Predictions * 0.25 + Nikhil’s Predictions*0.75)
- I looked at their code, but I don’t quite understand their ensembling solution. Also, I’m not sure if this code was the final one they used:
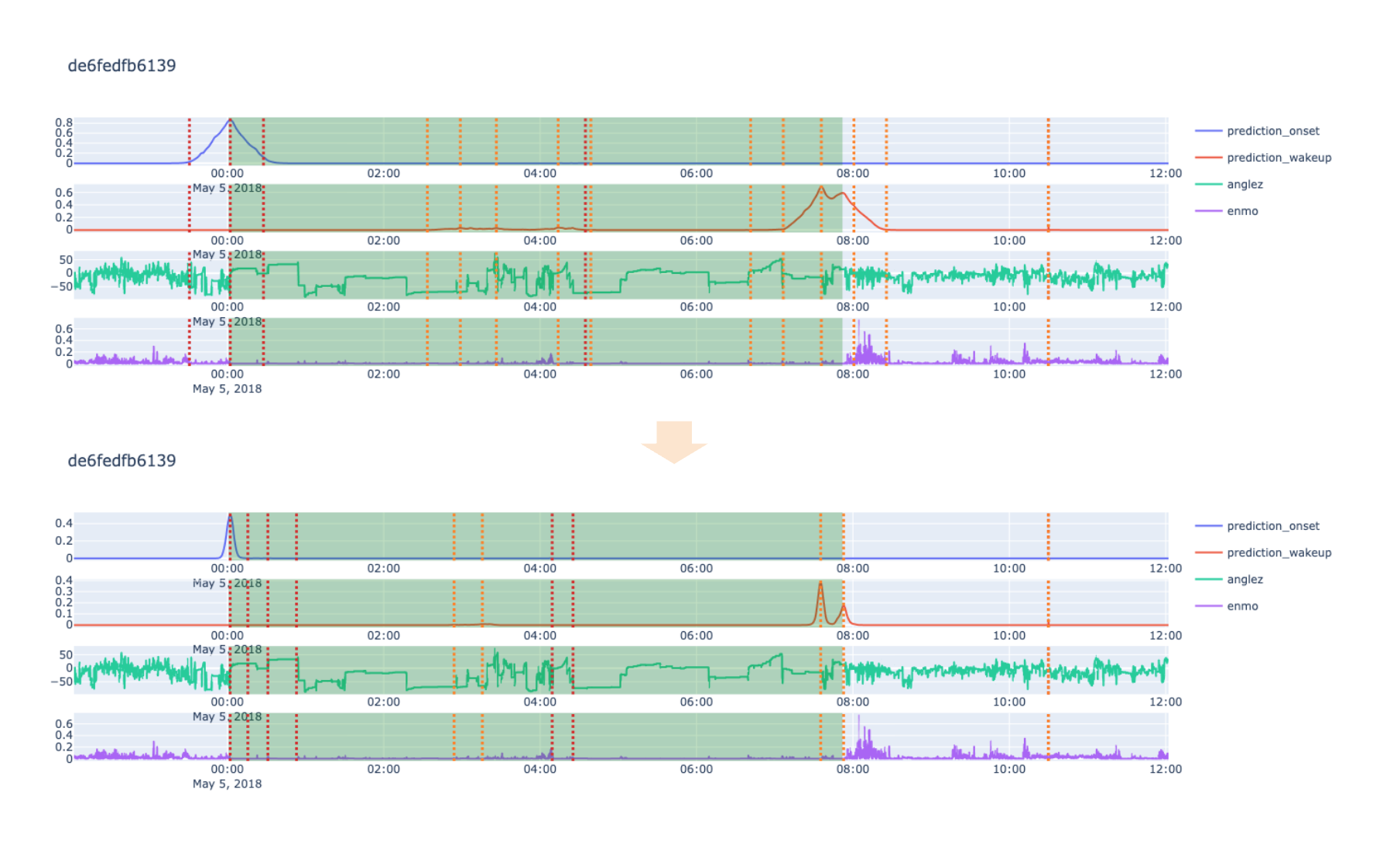
Takeaways
- In time series problems where are you identifying events within the series (not predicting future values), you can double your training data (and get better results) by reversing all the events in the time series.
- When postprocessing is annoying (e.g. there’s a constraint where there’s only two awake/onset events a day), you can use two models:
-
- The first to give you probability distributions of where the event is
-
- The second to interpret these peaks and sharpen the result
- Cause simply taking the max points won’t yield the best results
-
- You can use Weighted Boxes Fusion (WBF) ensembling rather than taking the mean of all model outputs
- Making anglez absolute can give you a boost in CV