Link: https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality
Problem Type: multi-class classification NLP
Input: Time series data of keystroke info. All alphanumeric characters were replaced with q so you couldn’t decipher the original essay text
Output: A score from [0, 6] (integer, incrementing in 0.5) of the resulting essay
Eval Metric: RMSE
Summary
- Given only keystroke information, predict a student’s essay score
- You can predict their score pretty well! with an RMSE of around 0.5
Important notebooks/discussions
Solutions
-
(1st) Lots of text cleaning. external data. large ensemble. trees + neural nets TabNet
- https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466873
- solution code: https://www.kaggle.com/code/tomooinubushi/1st-place-solution-training-and-inference-code?scriptVersionId=159806571
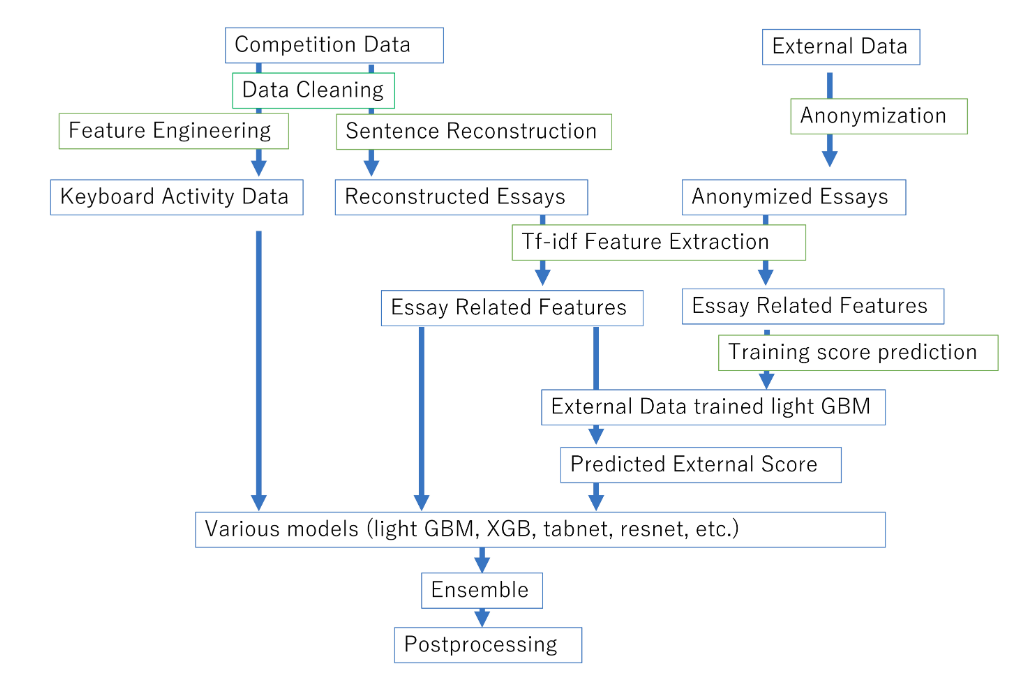
- cleaning:
- ftfy to fix unicode errors
- Discard events ten minutes before first input.
- Correct up times and down times so that gap times and action times are not too large (ten minutes and five minutes, respectively).
- other data quality issues specific to this dataset
- essay reconstruction text cleaning:
- If cursor position and text change information do not match with reconstructed text, search sequence with nearest fuzzy match.
- Correct Undo (ctrl+Z) operation if cursor position and text change information do not match with reconstructed text
- light autoML
- they didn’t use a transformer directly on the raw essay text
- used tf-idf features instead
- Once tf-idf features are extracted, I used truncated singular value decomposition (SVD) to reduce their dimensions to 64.
- used tf-idf features instead
- They gathered a lot of external data
- reading their solution, it seems like they tried TabPFN, but didn’t use it in their final submission
-
(3rd) Dieter’s team.
- https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466906
- 8fold cross validation
- identify domain shift: Deberta worked better on CV, while GBM were relatively bad on CV, but good on LB.
- That indicates a slight domain shift between LB and train set.
- Our guess is the essays might be split by topic or student year.
- DeBERTa
- replaced the obscurification character
qwithiorXwhen training debertas on the reconstructed essa text- prob cause the deBertas have these tokenizations in them: i, ii, iii, or X, XX, XXX
- Training own Tokenizer noticing that these specialized tokenizations led to better results, they trained their own tokenizer specifically for X, XX, or XXX.
- This led to much better results
- External Data Source: obfuscated the persuade corpus in a similar manner as the train dataset (for more data)
- They Train on external data first
- so DeBERTa they saw the competition data, it already knew how obfuscated text looked like
- Masked Language Modeling (MLM)
- They Train on external data first
- used a Squeezeformer layer to derive semantic features
- added three features:
- cursor position, etc
- Adding further keystroke features did not help, and we needed heavy dropout/augmentation on the three we added.
- The final components were as following
- deberta-v3-base trained with q replaced by i
- deberta-v3-large trained with q replaced by i (with first 12 layers frozen in finetuning, to avoid overfit) Freezing Layers
- deberta-v3-base trained with q replaced by X
- deberta-v3-base trained with custom spm tokenizer
- lasso feature importance for ensembling “we used positive ridge regression on Out-of-fold (OOF) predictions to determine blending weights.”
- actually, they used lasso
- https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466906#2596622
- They basically took yhat (that each deBerta outputted) as input features to a ridge regression that was trained to predict y
- ridge regression tells you feature importance:
- “Deberta1’s predictions are 30% important”
- “Deberta2’s predictions are 50% important”
- “Deberta3’s predictions are 20% important”
- you can use the importance info to weigh the ensemble
- ridge regression tells you feature importance:
- They basically took yhat (that each deBerta outputted) as input features to a ridge regression that was trained to predict y
- Important:
- “Deberta scores were relatively stable compared to each other; likewise GBM models.”
- So we trained a Lasso on Deberta only predictions; and a separate Lasso on GBM only predictions.
- replaced the obscurification character
-
Postprocessing
- For some models we clipped predictions at [0.5,6.] but it did not really make a difference.
-
What did not help
- Using the deleted text
- Stacking
- Adding more keystroke features to the deberta based model.
- More squeezeformer layers
- https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality/discussion/466906
Takeaways
- External data was the key (1st, 2nd, and 4th used it)
- always use a neural net
- ppl tried to generate features from the reconstructed essay text (e.g. avg word length), but these tabular features can’t compare to a neural net