Link: https://www.kaggle.com/c/mlb-player-digital-engagement-forecasting
Problem Type: Time Series
Input: Game statistics for the current day
Output: a prediction of how engaged fans are with a specific player after a game
- there are 4 target columns, each representing the engagement level fans have with that player
- we are predicting the engagement levels 1 day after the game (i.e. 1 day after the x_train data)
- however, during the evaluation period, “The test data arrives in a data frame identical in format to train.csv, except it does not contain the target values.”
- so even though you got those engagement levels, you can’t use today’s engagement level to predict tomorrow’s engagement level. Since you don’t know what today’s engagement level is!
Eval Metric: mean column-wise mean absolute error (MCMAE)
Summary
- Note:
- Binary columns will have null values as well as zeroes. Zeroes will occur if a player had an opportunity to do something, but did not. Nulls will occur if a player never had the opportunity to do something
- e.g. a player who does not pitch on a given day cannot possibly pitch a shutout
- how did they solve this?
- Binary columns will have null values as well as zeroes. Zeroes will occur if a player had an opportunity to do something, but did not. Nulls will occur if a player never had the opportunity to do something
- Data issues:
- https://www.kaggle.com/c/mlb-player-digital-engagement-forecasting/discussion/253940
- targets are capped at 100, but each player’s target isn’t divided equally
- target1 for player 425772 is divided by 663077, while target1 for player 425784 is divided by 1753059
- I don’t completely understand this
- https://www.kaggle.com/c/mlb-player-digital-engagement-forecasting/discussion/253940
Important notebooks/discussions
Solutions
-
(1st) Lots of model testing, not much features
- https://www.kaggle.com/competitions/mlb-player-digital-engagement-forecasting/discussion/274255
- solution code: https://www.kaggle.com/code/ph0921/mlb-final-1/notebook
- target scaling using log(x)
- all the past targets were scaled with log(1+x) to reduce their partly extremely “peaked nature”
- in addition a target mask was added to mark if the target information was provided on the respective day or not:
- Since the targets would only be available up to a certain time, he used a is present bit to represent if the targets exist or not
- he did this because for up to 32 days of the competition, there won’t be data present

- Non categorical features were scaled to roughly the same order
- missing values were replaced by -1
- create enriching features first, then mix across time
- Adam optimizer with decreasing learning rate start: 2e-3 end: 5e-4
- tried LSTM, CNNs or a transformer, but the GRU layer performed the best
- normalization methods (batch norm, layer norm,…) didn’t work
-
(2nd) 1000 features engineered. lgbm, xgboost
- https://www.kaggle.com/competitions/mlb-player-digital-engagement-forecasting/discussion/274661
- cross validation: “We validated on the last month of data”
- hold-out cross validation
- target scaling using ()
- lgbm with D.A.R.T
-
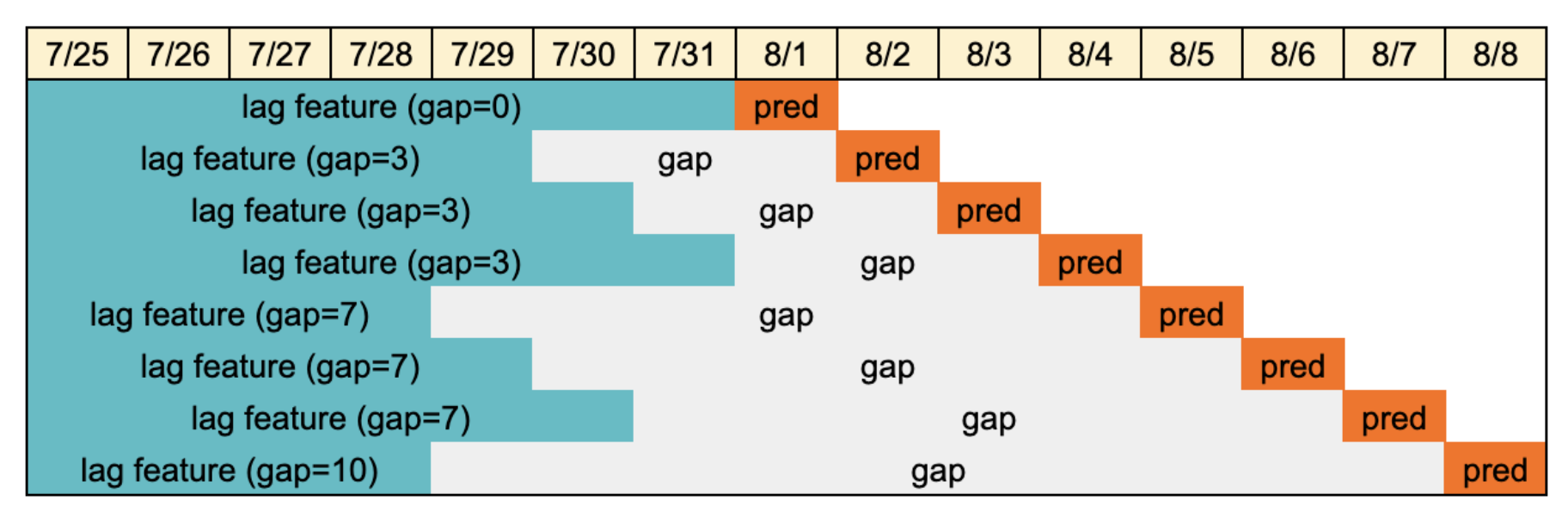
(3rd) varying gap lengths for CV
- https://www.kaggle.com/competitions/mlb-player-digital-engagement-forecasting/discussion/256620
- solution code:
- how they setup CV
- Debug code locally using the API emulator
- Test the robustness of my inference pipeline by “dropout” some of the data returned by the emulator (like chaos engineering) - sanity check
-
(5th) drop outliers
- https://www.kaggle.com/competitions/mlb-player-digital-engagement-forecasting/discussion/271345
- Special matches (like a player’s retirement match) should be removed from the data drop outliers
- e.g. Ichiro Suzuki got lots of engagement, despite doing poorly
- feature engineering
- made a submodel that predicts if a pitcher would pitch that day
-
(6th) lots of feature engineering
- https://www.kaggle.com/competitions/mlb-player-digital-engagement-forecasting/discussion/271890
- Makabe’s work
- derived many features from https://sabr.org/sabermetrics - stats about baseball
- encapsulate team’s code in class
Takeaways
- Use an is present bit if you expect to only use your target variable for a period of time
- You need a lot of feature engineering with time series. Don’t be afraid to make 1000 features!
- but dataset length probably matters, cause this dataset was kinda big (8Gb)
- Lagged Features were very important (e.g. num pitches today - num pitches 30 days ago)