- rather than concatenating new signal (i.e. vectors from another part of the network) to the start of the attention layer (before we get the key vector), we are appending it to the attention score (the value we have AFTER we multiply key by query, but BEFORE we sigmoid that value)
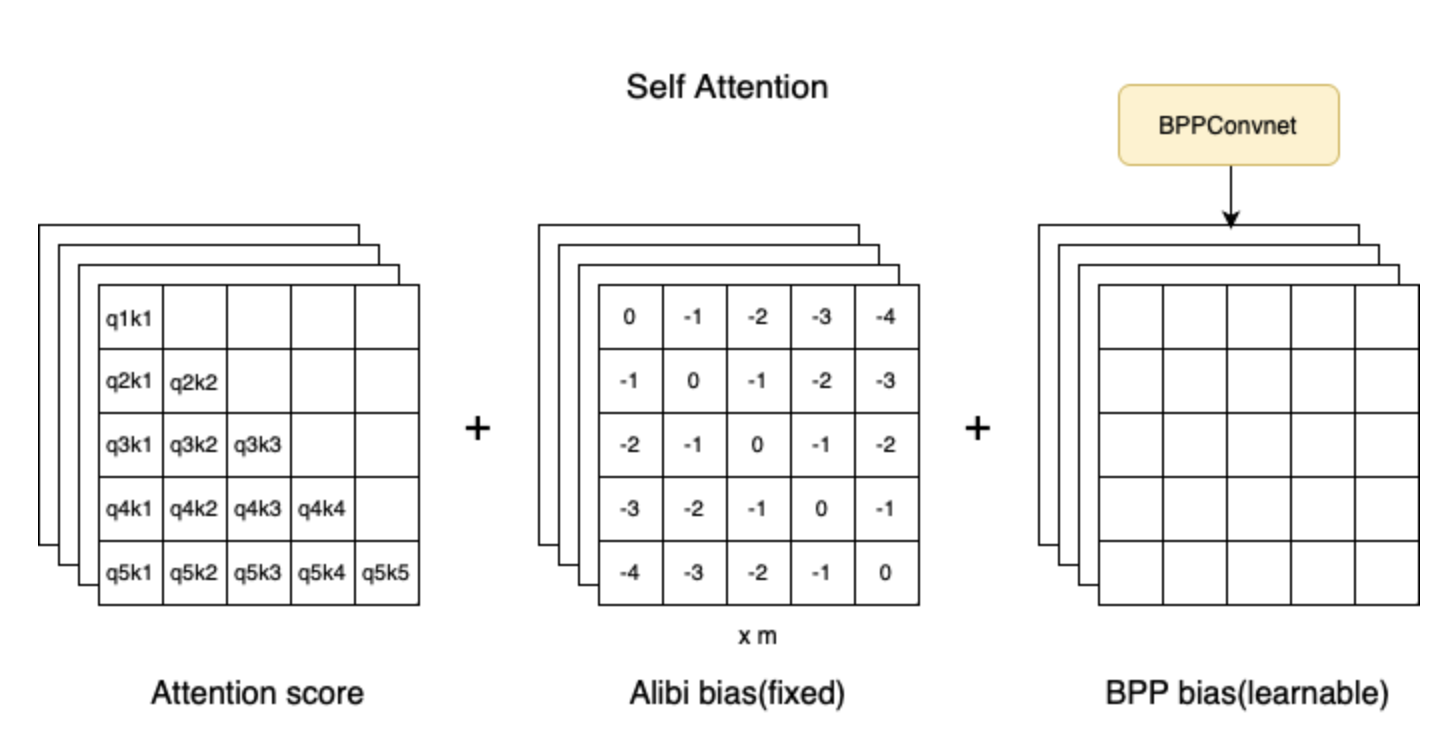
- ignore the alibi bias. the “new signal is from the BPP Convnet”