Link: https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
Problem Type: semantic segmentation
Input: 3D scans of the papyrus
- it’s hard cause ink may penetrate different depths of the paper
- Since it’s 3D and high res, the dataset is also massive
- These 3D scans are surface volumes:
- it’s called a surface volume cause it’s a 3D region of space around the virtually flattened paper
- it’s 3D cause ink can be inside OR ontop of the paper, so we need to know a 3D map of where it is in the paper
- this 3D volume has a height of 65 layers https://scrollprize.org/img/tutorials/ink-detection-anim2-dark.webm Output:
- it’s called a surface volume cause it’s a 3D region of space around the virtually flattened paper
- The output should be binary, with 0 indicating “no ink” and 1 indicating “ink”.
- I’m not sure if this is a 2D (x,y) or 3D (x,y,z) output
Eval Metric:
- F0.5 Score
- This weights precision higher than recall, which improves the ability to form coherent characters out of detected ink areas.
Summary
-
There are 2000-year-old scrolls left from Pompei (carbonized from the Vesuvius eruption)
- we can’t read them without breaking them
- so ppl 3D Xray-scanned the scrolls
-
The goal is to detect the ink in the 3D Xray scans.
-
the training data are (3D scans from the Herculaneum Papyri)
- The ground truth are the ink in these scrolls (found via infrared light)
- “We also provide hand-labeled binary masks indicating the presence of ink in the photographs.”
-
Glossary:
- What does “group” (a neural net dimension) mean? how is it different from channel?
- my guess: since we’re dealing with 3D inputs, a group is like one of the 65 layers of the height of the paper
- however, when we maxpool or downsample the height, it’s not exactly 65, so it’s called a group
- I think this because: ”- The channel/group combinations used were 5x7 and 3x9. In other words, the middle 35 or 27 layers of the 65 layers are used.”
- Temporal: We are looking at static scroll fragments, so why is there a temporal dimension keep getting mentioned?
- I think it’s cause we are looking at 3D data, so ppl name the extra dimension the “time” dimension, hence the temporal:
Solutions
- What does “group” (a neural net dimension) mean? how is it different from channel?
-
(1st - youtube vid) Stochastic Weights Averaging, remove easy examples
- https://www.youtube.com/watch?v=IWySc8s00P0
- discarded earlier layers of the papyrus when training (since it was blank) remove easy examples
- it also decreases bias in the model
- used BCELoss + DiceLoss
- BCE since it’s smooth. Dice since that is the evaluation for the competition
- used Stochastic Weights Averaging since the loss is noisy
- Used hold-out cross validation rather than kfold
- fragment 1 was their validation set
- if it was better, then retrain on all the data and submit to the leaderboard
- If it improved on fragment 1 AND the public LB, they would keep that improvement
- cosine annealing LR (didn’t do too much iteration here. it worked well)
- for each image of the scroll, they cropped it and fed each crop to the model
- found that large crops of the image is better
- this is the SAME amount of compute, even though the cropped img is larger, there are fewer crops of the scroll img
- used many segformer and unet models
- remove stray pixels
- they didn’t really try to do multiclass classification until the end
- multiclass as in: predict what is air, papyrus, and ink?
- training it was comparative to training the binary-based target network
- multiclass as in: predict what is air, papyrus, and ink?
- used vast.ai to train
- they were using small batch sizes (4,6) even across multiple GPUs
- thing they didn’t try yet:
- transform the data into the frequency domain. if some frequencies have no signal, the model will just assign 0 weight to it!
- discarded earlier layers of the papyrus when training (since it was blank) remove easy examples
- https://www.youtube.com/watch?v=IWySc8s00P0
-
(2nd) Focused more resources on training the encoder than the decoder. Used many channels (512)
- https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection/discussion/417255
- tattaka & mipypf’s part
- used 1/32 resolution reduce resolution
- this allows them to have more resources for training the encoder (more layers)
- using bilinear interpolation
- How did they figure out 1/32 was enough?
- Before starting the competition, when I read the host’s inkid repo, I found that they didn’t use upsampling.
- So when I actually calculated the maximum score that could be achieved by downsampling the label and undoing it, I found that I could get 0.98, so I knew that 1/32 resolution was enough.
- Preserving temporal and segmentation information:
- tbh I don’t understand this. but it seems really important
- https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection/discussion/417255#2304587
- “The input of the 2D encoder is (bs * groups, ch, h, w) and the output after going through the neck is (bs * groups, 512, h//32, w//32). Then permute it to (bs, ch, groups, h//32, w//32) and feed it to 3D CNN.”
- “This is impressive! I tried feeding (bs, groups, h, w) to 2D encoder (changing to → (bs, output channel, h, w)) and subsequently to 3D encoder but this approach has problem to lose temporal information. But using your method, it can be possible to retain temporal information and segmentation information at the same time.”
- Why is the first index of the 2D encoder bs * groups?
- should it be (bs, ch, groups, h, w)?
- maybe each batch is part of the same page? so it doesn’t matter that the groups dimension is mixed in with the batch size?
- tbh I don’t understand this. but it seems really important
- The normalized each image normalize features
# img: (bs, layers, h, w) mean = img.mean(dim=(1, 2, 3), keepdim=True) std = img.std(dim=(1, 2, 3), keepdim=True) + 1e-6 img = (img - mean) / std- This normalization is per batch size it seems? not normalized against the entire dataset?
- GroupKFold
- 3 groups: ink_id=0, 1, 2
- not sure what 2 is?
- 3 groups: ink_id=0, 1, 2
- model layers:
- used percentile thresholding. (0.93 was best!)
- test time augmentation (tta)
- h/v flip
- Switch tta each time stride
- used 1/32 resolution reduce resolution
- yukke42’s part
- used Swin-Unet (in the decoder) to expand image patches to upscale low resolutions 3D images
- downsample and upsample output
- output resolution is downsampled to 1/2 or 1/4, then upsample with a bilinear interpolation
- label smoothing
- regularization:
- ignore edge of output prediction
-
(3rd) Many U-nets with small resolution and Split up fragment 2 to have more training data,
- https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection/discussion/417536
- solution code:
- only uses ir-CSN as the 3d encoder with a simple mean pooling bridging to 2d decoder
-
Cross validation:
- originally used all 3 scroll fragments as 3 folds
- but fold 2 scored the worse
- guessed that it’s because the model didn’t see enough of fold 2
- https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection/discussion/401667
- so they split it into 3 individual folds (now they have 5 folds)
- this histogram explains why fragment 2 scores the worse: https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection/discussion/403348#2235071
- but fold 2 scored the worse
- originally used all 3 scroll fragments as 3 folds
-
Choosing the number of slices
- each fragment has 65 layers
- but using all 65 layers may be expensive. so they wanted to choose a good number of layers to use
- they experimented
8*islices where i=1, 2, 3, 4, 6. 24, 32 or 48- these all worked well. They chose to use 24 slices
- each fragment has 65 layers
-
Choosing the patch size
- used 224x224 (resulting in 13272 samples)
- larger patch sizes means that the model can read the entire character,
- but it’ll have much fewer samples - leading to overfitting
- A 864x864 patch size easily overfit within 2 epochs
- The best single big resolution model is 576x576 patch size r152 type unet on fold 5, scoring 0.77 locally
- used 224x224 (resulting in 13272 samples)
-
Models
- really loved https://www.kaggle.com/competitions/nfl-player-contact-detection/discussion/391635
- eventually used openmmlab’s implementation + pretrianed weights (most likely their unet implementation)
- after reading some solutions, we found that the channels of decoder is the most unconcerned part
- their decoder was inspired by https://github.com/selimsef/xview3_solution
- really loved https://www.kaggle.com/competitions/nfl-player-contact-detection/discussion/391635
-
augmentation
- used mixup and cutmix
- Segmenting on normalized pixels works: https://www.kaggle.com/code/yoyobar/3d-resnet-baseline-inference normalize features
- We set the ShiftScaleRotate’s rotate_limit to 180
- adamw optimizer, onecycle scheduler
- skipped a few things
-
inference
- used smaller cropping stride comparing to which we use in training.
- I guess it’s more accurate
- DIDN’T USE THRESHOLD SELECTION - just used 0.5
- no test time augmentation (tta)
- used smaller cropping stride comparing to which we use in training.
-
Tried but didn’t work
- 2d models
- pure 3d models
- stacked unet which use 2d denoiser
- training a 3d denoiser
- classification branch for stronger supervision
- add maxpooling and conv layers between encoder and decoder
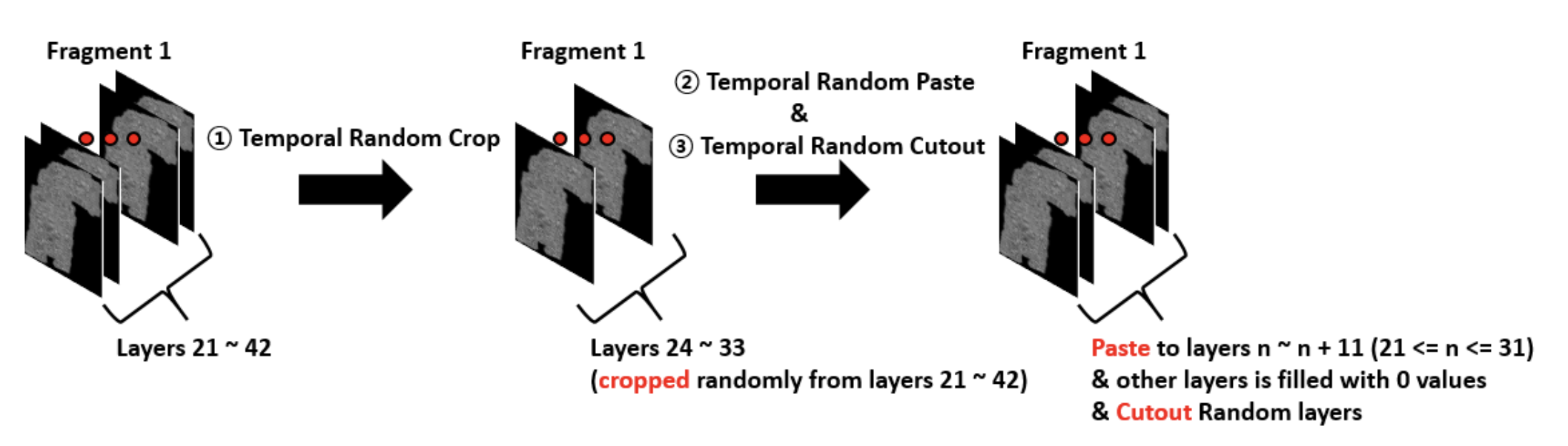
Important notebooks/discussions
- Understanding how ink is spread on the papyrus. Why fragment 2 is hard to predict for
Takeaways
- Image segmentation uses a decoder + encoder
- spend more time on the encoder
- smaller decoders are good enough
- ppl didn’t find that much success with test time augmentation (tta). If they did, it was either only 1 or 2 augmentations.