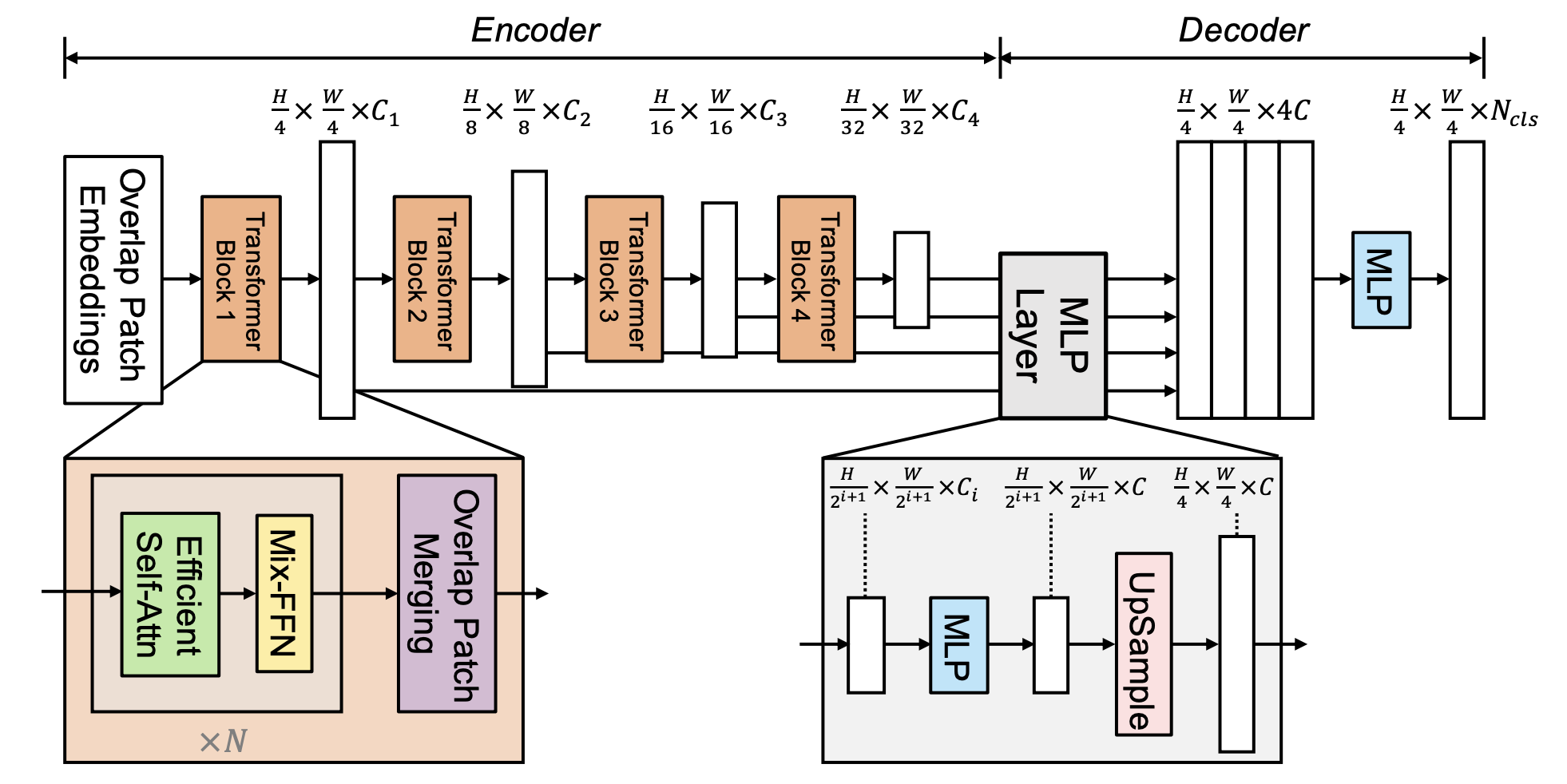
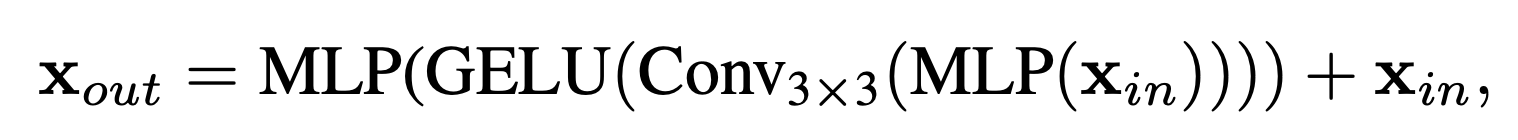a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders.
It does not need positional encoding
so if you don’t need to interpolate positional codes (leads to worse performance) when doing inference on a diff resolution
How do they have the self attention layer without positional embeddings?
“We argue that positional encoding is actually not necessary for semantic segmentation”
Instead, we introduce Mix-FFN which considers the effect of zero padding to leak location information
Mix-FFN can be formulated as:
where xin is the feature from the self-attention module.
this still doesn’t answer why positional embeddings aren’t needed. If xin is AFTER the self-attention module, there are no positional embeddings going INTO the self-attention module.
since the transformer encoder is O(n^2), they used a reduction ratio technique to reduce the length of the sequence.