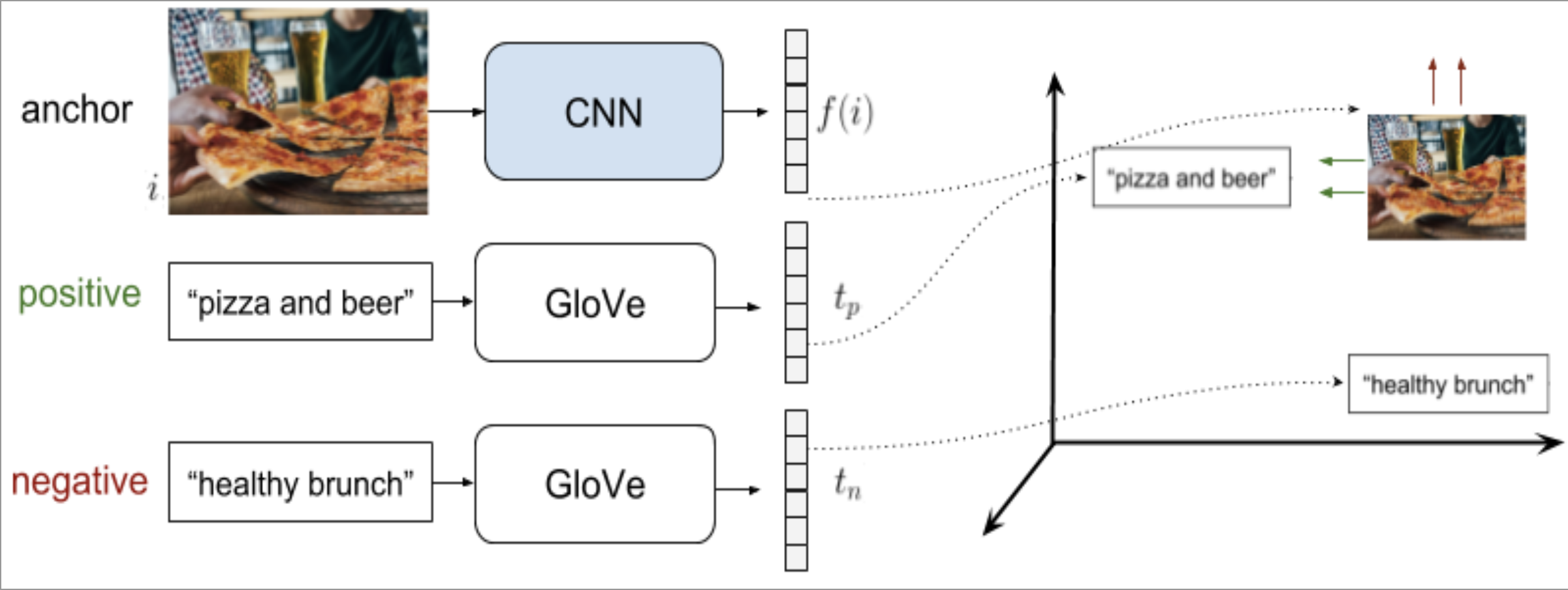
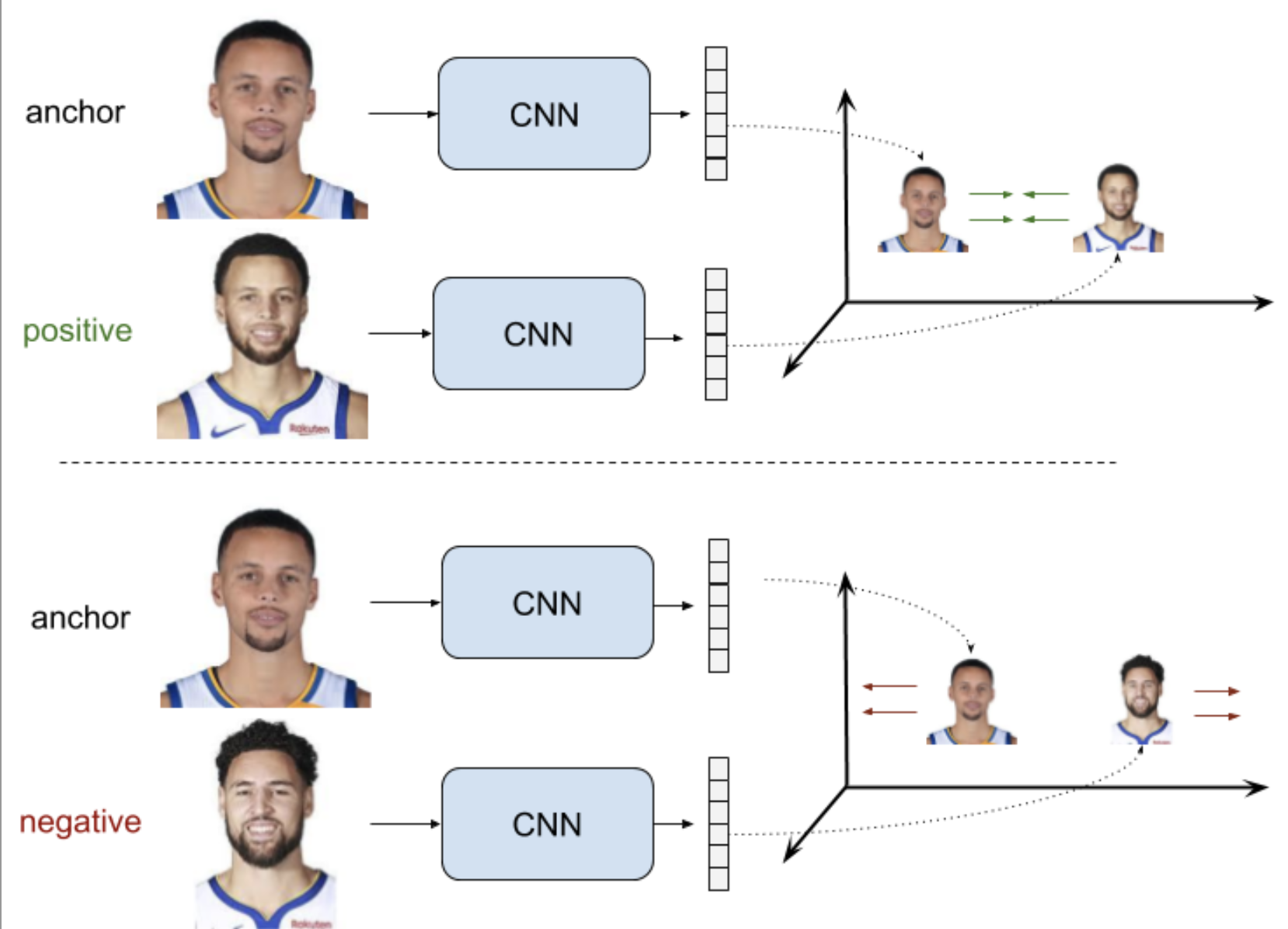
The objective is that the distance between the anchor sample and the negative sample representations d(ra,rn) is greater (and bigger than a margin m) than the distance between the anchor and positive representations d(ra,rp).
in his research, he found that triplet ranking loss worked better to teach the model multimodal representations of data
e.g. given an image, caption it.
the CNN needs create image embeddings that is close to the GloVe embeddings
this works better than standard Cross-Entropy Loss
“To choose the negative text, we explored different online negative mining strategies, using the distances in the GloVe space with the positive text embedding”
this was smart because the negative mining examples will have a close embedding with the positive examples