Link: https://www.kaggle.com/c/icr-identify-age-related-conditions
Problem Type: binary classification
Input:
AB-GLFifty-six anonymized health characteristics. All are numeric except forEJ, which is categorical.
Output: predict if a person has any of three medical conditions (class 1) or not (class 0)
- Note: the Supplemental metadata has
B,D,GThe three age-related conditions. Correspond to class1.- NOTE: (1st) did not use this (since it isn’t available for the test set)
Eval Metric:
- The submitted probabilities for a given row are not required to sum to one because they are rescaled prior to being scored (each row is divided by the row sum)
- since we’re predicting class 0 and class 1, and it’s rebalanced, this is just a binary classification
Summary

- yep :) This is a fun competition
- 7,327 Competitors, 6,430 Teams
- Note: All of the data in the test set was collected after the training set was collected.
- Why did people think that CV didn’t Work
- small dataset: only 617 rows (very unstable CV - easy to overfit)
- this makes the loss not very continuous
- there were also 50+ features, so possibly the curse of dimensionality?
- only 18% of the data is class1:
- class1 examples are weirdly distributed
- the test data is taken after 2020, but there isn’t enough data to form a trend
- so do we treat it like a time series problem? not sure
Transclude of ICR---Identifying-Age-Related-Conditions#^313qla
- the test data is taken after 2020, but there isn’t enough data to form a trend
- small dataset: only 617 rows (very unstable CV - easy to overfit)
- Why did people think their CV was good, but got bad scores?
- there is a component of luck
- people trusted their CV a bit too much, and didn’t do remove easy examples (2nd)
- they spent too much time overfitting yourself
- What is reweighing?
- Not sure. Maybe it’ ” the reweighting is done in a way such that the class predictions are more balanced overall across all test data rows”
- Glossary:
epsilonis the date for each row in the (optional dataset)greeks.csv
Important notebooks/discussions
- Baseline notebook and EDA
- https://www.kaggle.com/code/gusthema/identifying-age-related-conditions-w-tfdf
- positive samples (class 1) only account for 17.50% of the data
- https://www.kaggle.com/code/gusthema/identifying-age-related-conditions-w-tfdf
- Explaining why the problem is hard (why CV is hard to make)
- https://www.kaggle.com/code/raddar/icr-competition-analysis-and-findings
- The BN column is age distribution matching
- The Population is segmented by the
EJcolumn- when
EJ == 0,EH = 0.5. This means there is no reason to encodeEJdrop redundant columns
- when
- the mean is the percentage of the data that is class 1 ^313qla
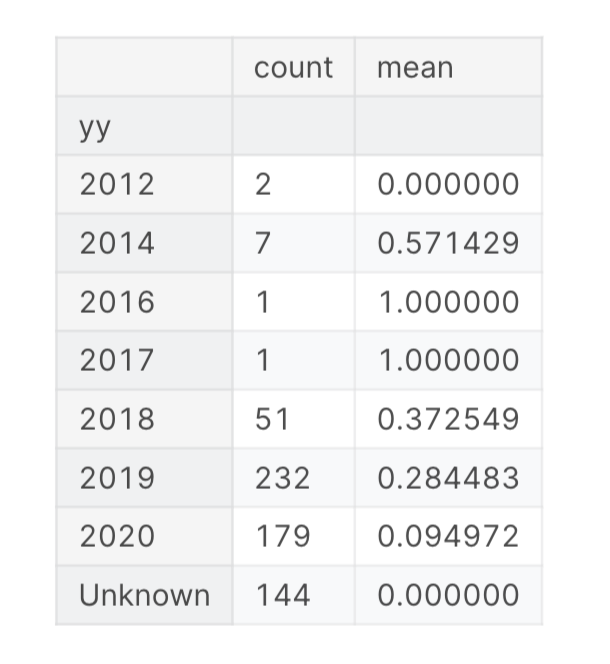
- notice how the mean fluctuates. NOTE: we do NOT KNOW THE YEAR IN THE PRIVATE TEST SET
- since this is derived from the
greeksdataset, which isn’t available for test
- since this is derived from the
- NOTE: the hidden set was recorded after the traning dataset was collected, so some time influence may be important.
- however, this fluctuation doesn’t show a pattern
- They ran a TSNE and K-nearest neighbour (KNN) on the data.
- Found that for all the
class 0examples, there are only 8class 1examples that are near it - basically: after clustering, there are very few
class 1examples that are intermixed with theclass 0examples. - This means that there are very FEW “hard examples”.
- This is BAD because correctly deducing the correct class for hard examples is what makes the model stronger
- however, this method of finding “close” samples is fiddly. if you use diff features, clusters could be easier/harder to form
- Found that for all the
- “The fact that the evaluation metric is almost entirely determined by the presence or absence of the hard cases (false negatives) means that any CV (or indeed LB) evaluation is not going to be a continuous function, let alone differentiable. This explains the difficulties in getting a robust CV scheme we’ve seen in this competition (as well as the crazy leaderboard).”
- using the greeks.csv supplimental data
- https://www.kaggle.com/code/sugataghosh/icr-the-devil-is-in-the-greeks
- The key takeaway from this notebook is the observation that these supplemental metadata, in particular the categorical variables
Beta,GammaandDelta, are far more powerful in predictingClass, compared to the features provided in thetraindataset. - It may be helpful to first predict the categorical variables
Beta,GammaandDeltain the metadata for the test set, and then predict theClassbased on the predicted metadata variables. - NOTE (1st) didn’t use this supplimental data cause it’s not in the test set
- introducing TabPFN and reweighing
- https://www.kaggle.com/code/muelsamu/simple-tabpfn-approach-for-score-of-15-in-1-min
- code
def predict_proba(self, X): X = self.imp.transform(X) ps = np.stack([cl.predict_proba(X) for cl in self.classifiers]) p = np.mean(ps,axis=0) class_0_est_instances = p[:,0].sum() others_est_instances = p[:,1:].sum() # we reweight the probs, since the loss is also balanced like this # our models out of the box optimize CE # with these changes they optimize balanced CE new_p = p * np.array([[1/(class_0_est_instances if i==0 else others_est_instances) for i in range(p.shape[1])]]) return new_p / np.sum(new_p,axis=1,keepdims=1)
- Similarity CV (doesn’t work): “A novel way to tackle the problem”
- https://www.kaggle.com/competitions/icr-identify-age-related-conditions/discussion/414856
- “instead of focusing on individual of the sample, we consider a couple of individuals (𝑖,𝑗) and try to guess if they belong to the same class”
- Now our new training dataset has samples, the new validation dataset has samples
- where is the size of our validation set
- kaggle master: “I think it would work well if the two classes were better separated overall. Sadly, I don’t think it will be competitive for this dataset”
- https://www.kaggle.com/competitions/icr-identify-age-related-conditions/discussion/414856
Solutions
-
(1st) Temporal Fusion Transformers (TFT) + workable CV + alternative targets (auxiliary objective) for “hard to predict”. No Feature Engineering
- https://www.kaggle.com/competitions/icr-identify-age-related-conditions/discussion/430843
- solution code: https://storage.googleapis.com/kaggle-forum-message-attachments/2384935/19562/adv_model_training.ipynb
- The “greeks.csv” was useless. I think, because we have no greeks for the test data.
- Gradient boosting was obviously overfitting
- feature engineering led to overfitting
- Cross validation
- 10 folds cv, repeat for each fold 10-30 times, select 2 best models for each fold on CV (yes, cv somehow worked in this competition!).The training was so unstable, that the cv-scores could vary from 0.25 to 0.05 for single fold, partially due to large dropout values, partially due to little amount of train data. That’s why I picked 2 best models for each fold.
- in the training notebook:
- their CV is using StratifiedKFold
- they are only printing the lowest validation loss (not using? select 2 best models for each fold on CV)?
- the weights are saved to their own h5 file. so maybe they’re just picking the right one based on the score
- I can confirm that for each of the 10 train-validate splits, they are running them 10 times.
- their main model was Temporal Fusion Transformers (TFT)
- I guess since we have data for different years, a time-based model could be helpful here
- but this isn’t a forecasting problem so I’m not sure how they are using TFT
- ok I understand the TFT model architecture now. Although the train_x he passed into TFT isn’t time-based it’s fine
- cause the model is pretty good at automatically “selecting which features to use” (via learned weights), regardless of time variables
- I looked at his code: He didn’t use the LSTM that TFT used. He mainly just used the layers that did feature selection
- he didn’t even use the attention layer at the end of TFT
- his model was just stacking 3 variable selection layers ontop of each other, and called it a day.
- used the Smish activation function
- I guess since we have data for different years, a time-based model could be helpful here
- What did work:
- DNN based on Variable Selection Network
- No “casual” normalization of data like MinMaxScaler or StandartScaler, but instead a linear projection with 8 neurons for each feature.
- Huge values of dropout: 0.75→0.5→0.25 for 3 main layers.
- Reweighting the probabilities in the end worked really good
- The cv was some kind of Multi-label. At first I trained some baseline DNN, gathered all validation data and labeled it as follows: (y_true = 1 and y_pred < 0.2) or (y_true = 0 and y_pred > 0.8) → label 1, otherwise label 0. So, this label was somthing like “hardness to predict”. And the other label was, of course, the target itself.
- target engineering
- Added a hardness to predict label
- Trained some baseline DNN, gathered all validation data and labeled it as follows: (y_true = 1 and y_pred < 0.2) or (y_true = 0 and y_pred > 0.8) → label 1, otherwise label 0
- this DNN is: “literally the model with 2 VariableSelectionFlow layers instead of 3”
- Added a hardness to predict label
- feature engineering
- imputed missing values with the median filling training data (impute data) (didn’t test mean / K-nearest neighbour (KNN))
- didn’t resample or preprocess for noise reduction
- comments
- “How much did you step 6 improve your model. If I get it right, you override original targets by the model’s out of fold prediction if the prediction is confident enough. I had something like that in mind but it seems it felt in a crack. I used this successfully in the past and I have seen recent competition winners share something similar too.” - CPMP, Kaggle Grandmaster
- “I didn’t override the original target, the tgt2 was used only for better splits during cross-validation. Step 6 improved the score by 0.02.”
- “In my experiments standardization of the data deteriorated the cv-score, though I don’t fully understand why”
- “It is a bit funny to see people thinking Time series should behave like I.I.D and stationary data . These deviations are not uncommon , particularly in fields like Finance. That’s why modelling for these data is still very challenging and overfitting them is very easy” - Serigne - competitions master
- “I remember clearly conventional belief that we are not even suppose to try neural network if we don’t have a sizeable data. I guess I’m dead wrong.”
- “I tried reducing dimensions with autoencoder, but it didn’t look very promising.” - Tilii - competitions master
- it took 10 hrs to train the DNN
- “And regarding balanced logloss - as I understand this, reweighting just stretches the probabilities in one or other side, but if they are in the middle (0.5) they stay there)”
- “How much did you step 6 improve your model. If I get it right, you override original targets by the model’s out of fold prediction if the prediction is confident enough. I had something like that in mind but it seems it felt in a crack. I used this successfully in the past and I have seen recent competition winners share something similar too.” - CPMP, Kaggle Grandmaster
-
(2nd) Dropped rows where date was unknown. catboost, xgboost, TabPFN
- https://www.kaggle.com/competitions/icr-identify-age-related-conditions/discussion/430860
- solution code: https://www.kaggle.com/code/opamusora/main-notebook
- filled Nan values with -100 filling training data (impute data)
- used a technique I saw in some other competition: reducing dimensions with umap and then labeling clusters with kmeans, it didn’t bring a lot of score, but it’s there (alternative targets (auxiliary objective)???)
- did feature permutation manually, dropped any cols that made score even slightly worse
- interesting that it worked
- used Catboost, xgb with parameters from some public notebook and TabPFN
- remove rows where feat=x to find unknown data clusters to remove easy examples
- removed rows where time (ƒrom
greeks) is None (23% of data), I noticed a weird cluster that was far away from all other data when playing with umap and it were rows with absent time- many people didn’t remove those rows. BECAUSE THE DATASET WAS ALREADY SMALL
- “it obviously dropped some score (since we remove a lot of easy class 0 ), but eventually I decided to keep it cause it would be better for general cases.”
- those “data points were really far from the main cluster so I decided to remove it anyway”
- “seems intuitive for me to drop data thats insanely far from most observations and also has a clear feature that distinguishes it from everything else” (in discord)
- removed rows where time (ƒrom
- permutation feature importance to select features
- they removed 20 features in the best model
- I checked the discord. They didn’t mention much about how they did the permutation (it was prob mentioned in a call)
- we wanted to try edit TabPFN to get embeddings and we had an idea to try fine tune tabpfn, but it didn’t work out.
- optuna didn’t work
- Stacking didn’t work
- used a simple 4-fold stratified kfold
-
(3rd) didn’t do much after the baseline - got lucky by NOT working on it too much and overfitting
- https://www.kaggle.com/competitions/icr-identify-age-related-conditions/discussion/430978
- solution code: https://www.kaggle.com/code/junyang680/icr-lightgbmbaseline
- create features through the ratio between different features
- didn’t do this in the end
- they didn’t even select the top k more correlated features (with the target) for their final submission
-
(4th) create models to predict alternative targets (Alpha, Beta, Gamma, Delta in
greeks), then use these as features- https://www.kaggle.com/competitions/icr-identify-age-related-conditions/discussion/431173
- solution code: https://www.kaggle.com/code/andrejvetrov/third?scriptVersionId=131958512
- Now for the key features of my solution.
- Recursive filling of gaps in features using regression on CatBoostRegressor (default hyperparameters),
- greeks[‘Epsilon’] Unknown were filled with greeks[‘Epsilon’].min()
- row_id - row number in train and in test when sorting by Epsilon
- they used the row ID as a feature???
- “I added this simple feature more intuitively for the reason that although the size of the dataset is small, it has a time component that must be taken into account somehow”
- SO EPSILON IS TECHNICALLY IN THE DATASET. IT’S THE ROW ID
- Trained models for each Alpha, Beta, Gamma, Delta and stacked these probabilities to be used as features.
- 5-fold cross validation and then simple averaging
-
(5th) create models to predict alternative targets (Alpha, Beta, Gamma, Delta in
greeks), then use these as features- https://www.kaggle.com/competitions/icr-identify-age-related-conditions/discussion/430907
- solution code: https://www.kaggle.com/code/celiker/icr-5-place-solution/notebook
- main points:
- Trained models for each Alpha, Beta, Gamma, Delta and stacked these probabilities to be used as features.
- Created lgbm imputer models for every feature even if it has no missing values on train data.
- note: Removing imputers didn’t effect the score, so the main strength is stacking greeks.
- Used RepeatedStratifiedKFold(n_splits=5, n_repeats=5) with a basic catboost model.
Takeaways
- (1st)‘s hardness to predict label prob made a big difference
- Use a deep neural network. Always. Even if you have little data. If you have a good CV, it’ll work.
- (1st) was inspired by https://arxiv.org/pdf/1912.09363.pdf
- (2nd) found success with TabPFN
- (1st) “feature engineering led to overfitting”. This requires blindly believing in your CV. which is so painful to accept
- Do brave things:
- (2nd) removed the rows that didn’t have a date in the aux data
- prob because they were all class 0
- this was very brave since the dataset was already small
- (2nd) removed the rows that didn’t have a date in the aux data
- if there’s a competition with potential for large shakeup, investing more time could mean you’re overfitting yourself to the problem (and make an overfitted model)