- you use the intermediate layer results to get the final output
- obv, you weigh each layer’s results differently (these weights are trained)
- first seen in the Elmo paper (the final embedding representation is a weighted average of all LSTM layers)
https://www.kaggle.com/competitions/google-quest-challenge/discussion/129978
- We use the output of every layer of a single transformer model in which we put 512 question and 512 answer tokens. For roberta-base that will give us twelve 512x768 tensors (for roberta large it would be 24 512x1024 tensors). We then average over the 512 tokens for each layer which results in twelve 768 representations. We then take a weighted sum of these 12 representations (where the weights for adding the representations are trainable!). This results in a 768 representation. The weighted average of all layer outputs enables to capture low level features in the final representation which was quite important for some answer related targets. Finally, we add a single prediction head for getting our targets.
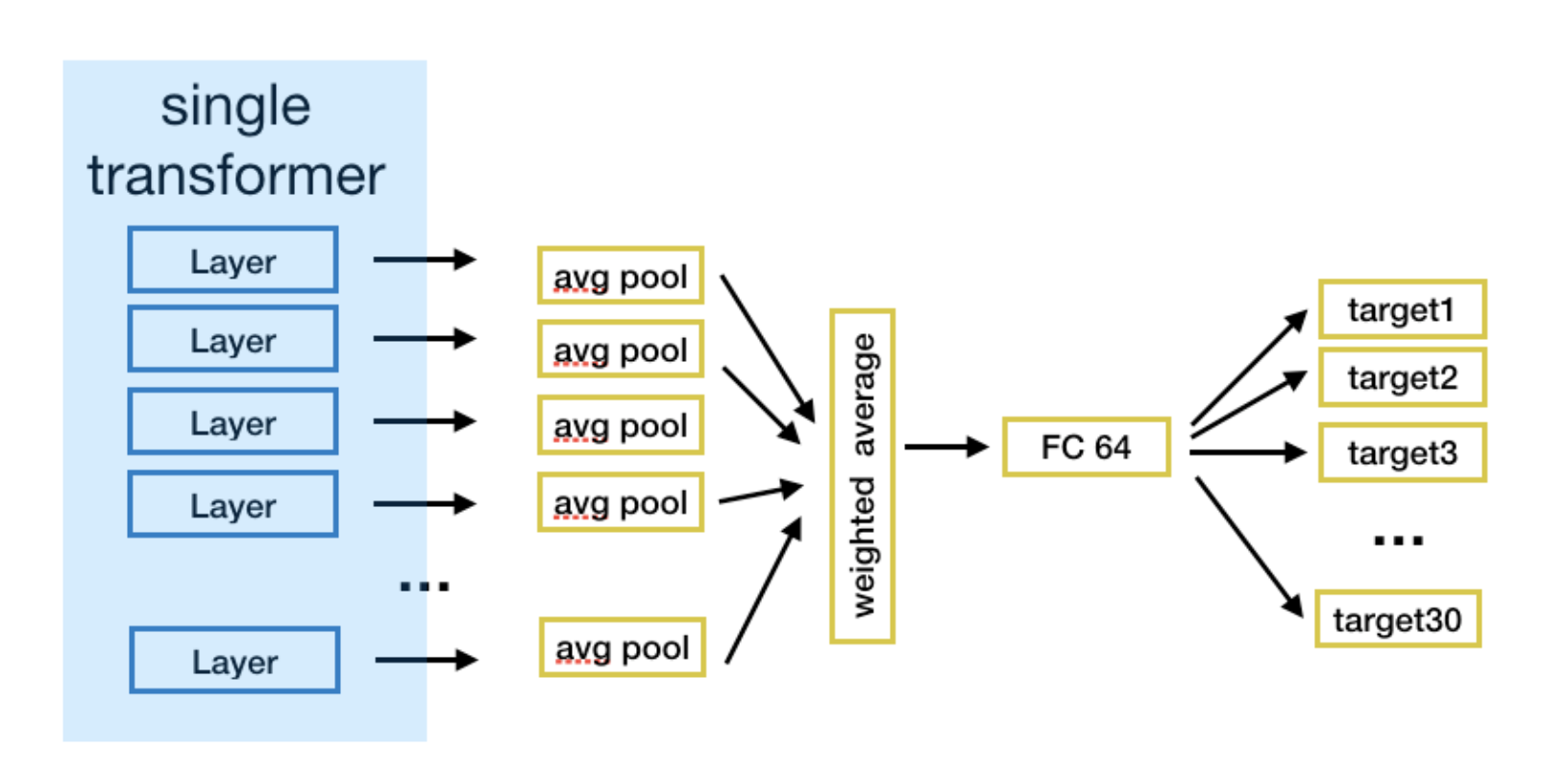
- FC stands for fully-connected layer