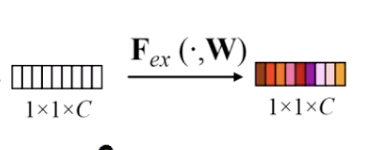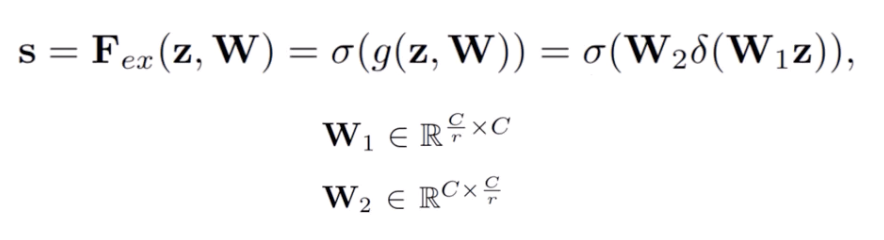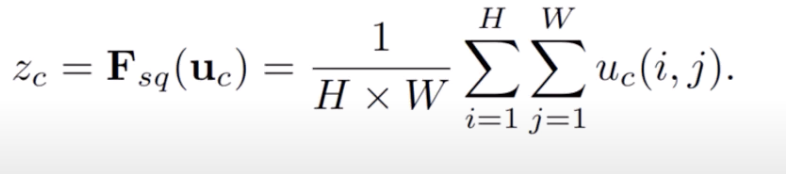in an image conv net, we have different channels (e.g. RGB)
but some channels might be more important than other channels (e.g. Green is more important if our model is classifying grass)
so our conv net should pay more attention to that channel
cause in traditional conv nets each channel gets processed equally in subsequent layers.
although info from each layer is merged together at the final layer to get the output, the model doesn’t have a mechanism to “pay extra attention to specific channels” in intermediate layers
before squeeze and excitation, there was no way to assign extra attention to this
the. genius is that this method is very efficient
How it works:
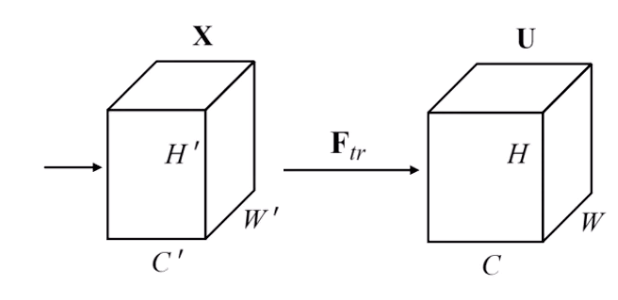
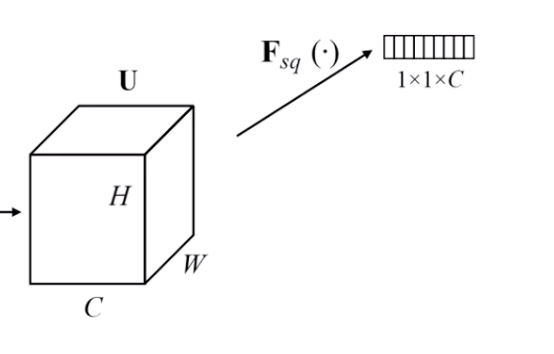
during a convolution, we get this:
our convolution creates the volume of data on the right
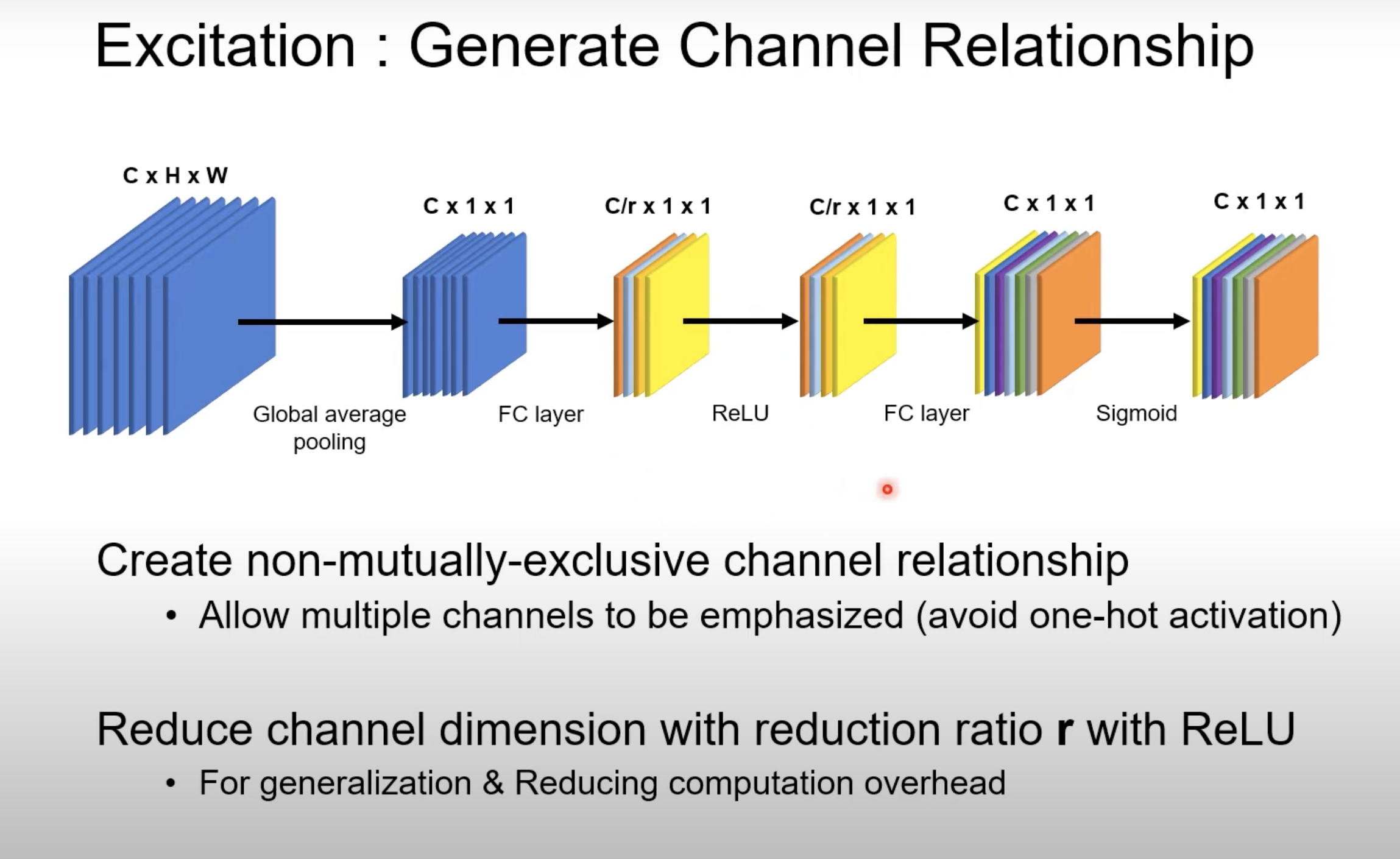
now, for each channel in C, we need a single number to represent how important that channel is
so we squeeze it into a 1x1xC value:
the simplest way is to use global average pooling to get this 1x1xC
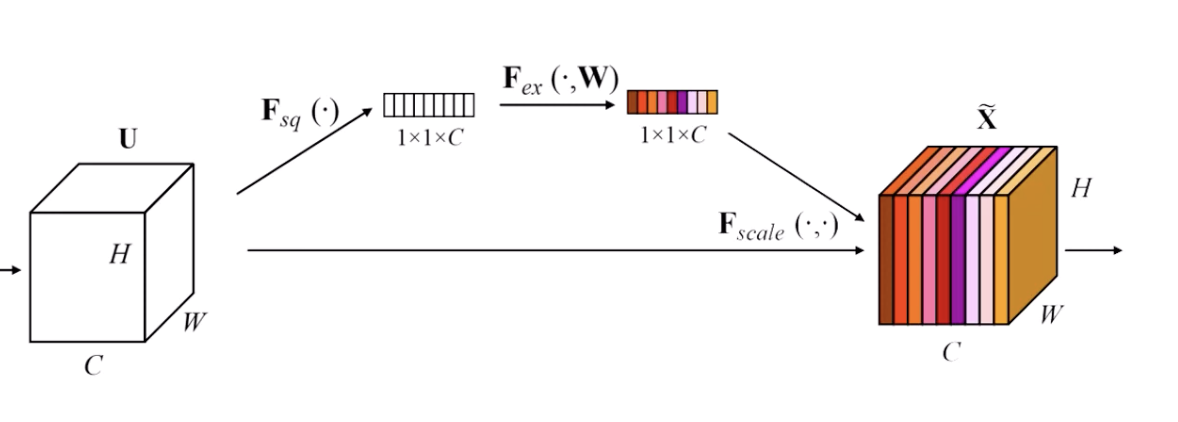
but having this representation isn’t enough to know which channel is more important than other layers
this is why we need the excitation layers (which acts as the attention mechanism)
these are the excitation layers
notice the sigmoid, which if you recall from LSTMs acts as a “gate” that determines how important information is
notice how the excitation layers shrinks the dimension from C to C/r (the reduction ratio)
this feels like a convolution. I guess it tells the model to only learn the important things
finally, the dimension goes back from C/r to C (like an autoencoder)
finally, we have the scale operator, which multiplies each coefficient of the sigmoid operation (i.e. the importance) with the corresponding channel in the output of the convolution:
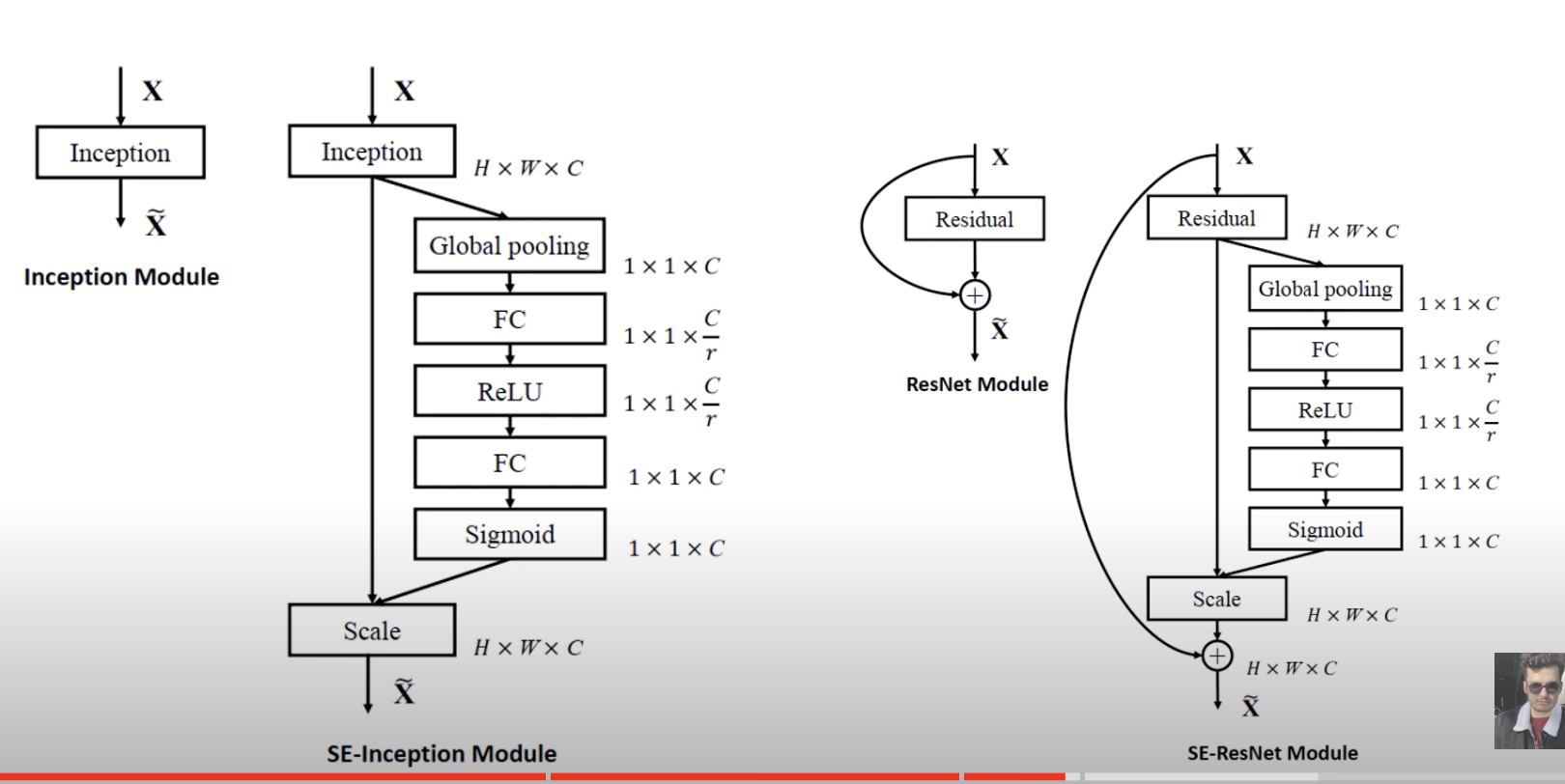
Here’s how to organize your layers with squeeze and excite if you have residual layers: