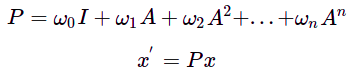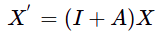In supervised graph classification, the task is to solve an end-to-end whole-graph classification problem (i.e. the problem of as-signing a label to the entire graph).
hese supervised approaches [ 33 , 36, 45 , 61 ] learn an intermediate representation of an entire graph as a precondition in order to solve the classification task.
but is heavily biased towards maximizing performance on the classification task of interest.
the problem: if we change the topology of the graph, won’t the adj matrix change? wouldn’t our matrices w be invalid?
we’re only learning weights for this specific graph
I think the article is just keeping it simple and making an analogy. In reality we’ll just use an aggregation function for hte neighbouring hidden weights (so we aren’t training for a specific graph topology)
Note that higher orders of A just means that we are considering node features u-hops away where u is the power of the adj matrix (this is a property of adj matrices. look it up!)
why even have higher orders of A?
so we can get more data from further neighbours.
If this was an image net, this is analogous to increasing our kernel size for the convolution (3x3 → 5x5)
message passing:
where X are ALL the feature vectors for each node in the graph
Feature passing is an approximation of Graph convolution. instead of different powers of A, we get the next X for the next layer using only one power of A
note that we add I to the matrix, so we also add our OWN features to the weighted sum of neighbouring feature vectors to get our next feature vector
it’s called message passing since we’re only doing 1-hop vector transfers from neighbouring vectors
normally, in a MP-GNN, we approximate graph convolutions by applying message passing multiple times (we iteratively do this operation with more layers in our GNN)
It is possible to use graph Laplacian instead of adjacency matrix to pass feature differences instead of feature values between nodes.
isn’t the Laplacian matrix just an adj matrix but with the diagonal representing the number of indegrees of each node
TLDR: you can create the Laplacian from the adj matrix. they are one-to-one
basically, we’re just doing a weighted average of the neighbouring embeddings * by the weight matrix