https://www.youtube.com/watch?v=lpFufRf9jFI
- the main idea is this:
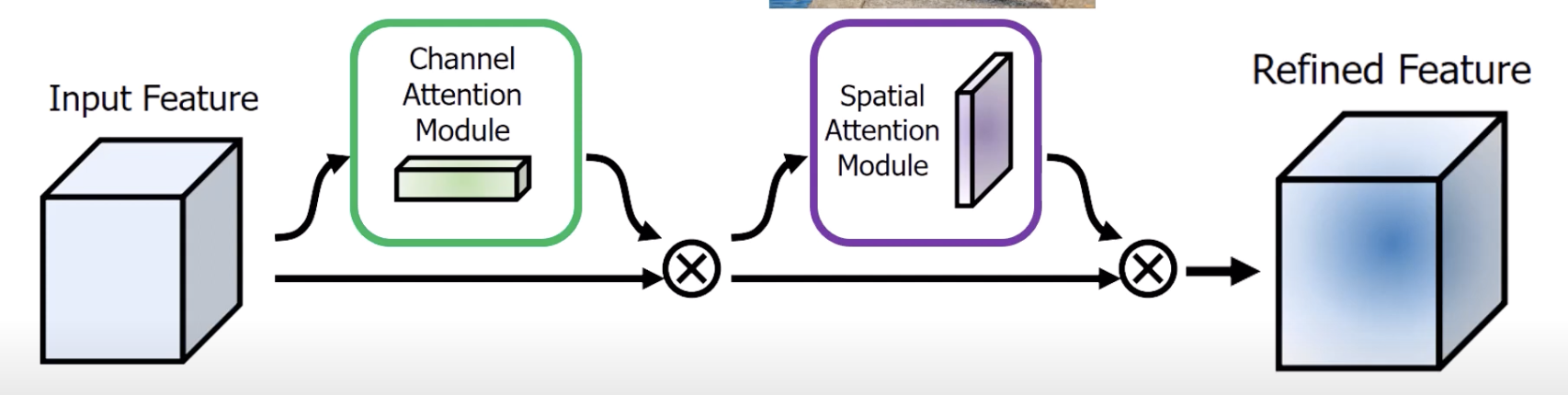
- if you give the model the ability to learn that specific areas are more important than others, then hopefully we’ll get a better result
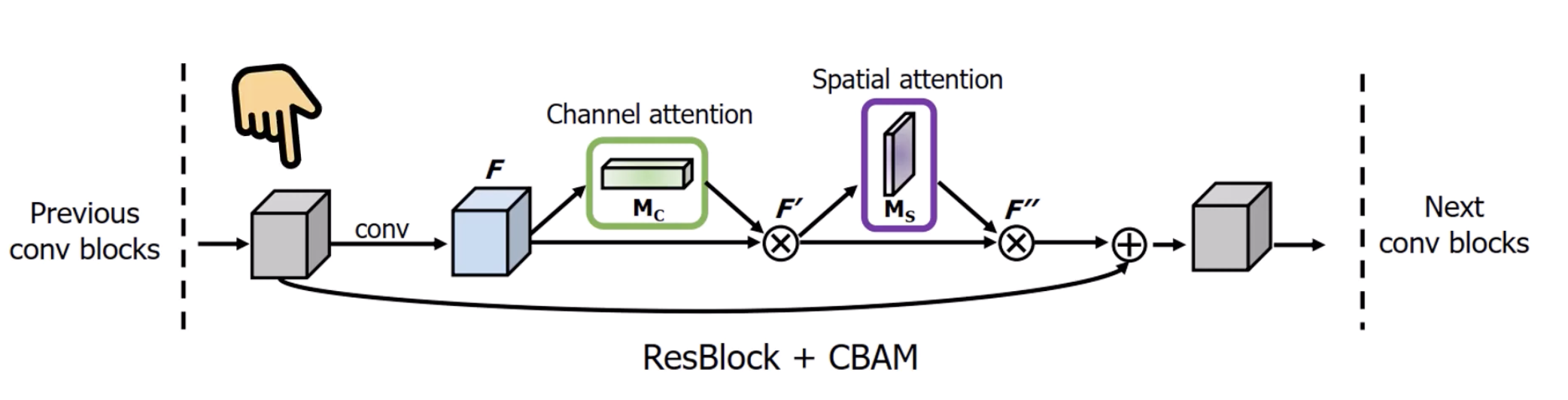
- the authors realized that applying a channel attention module before spatial attention modules works the best
- no intuition, just emperical trials
- How the channel attention module works:
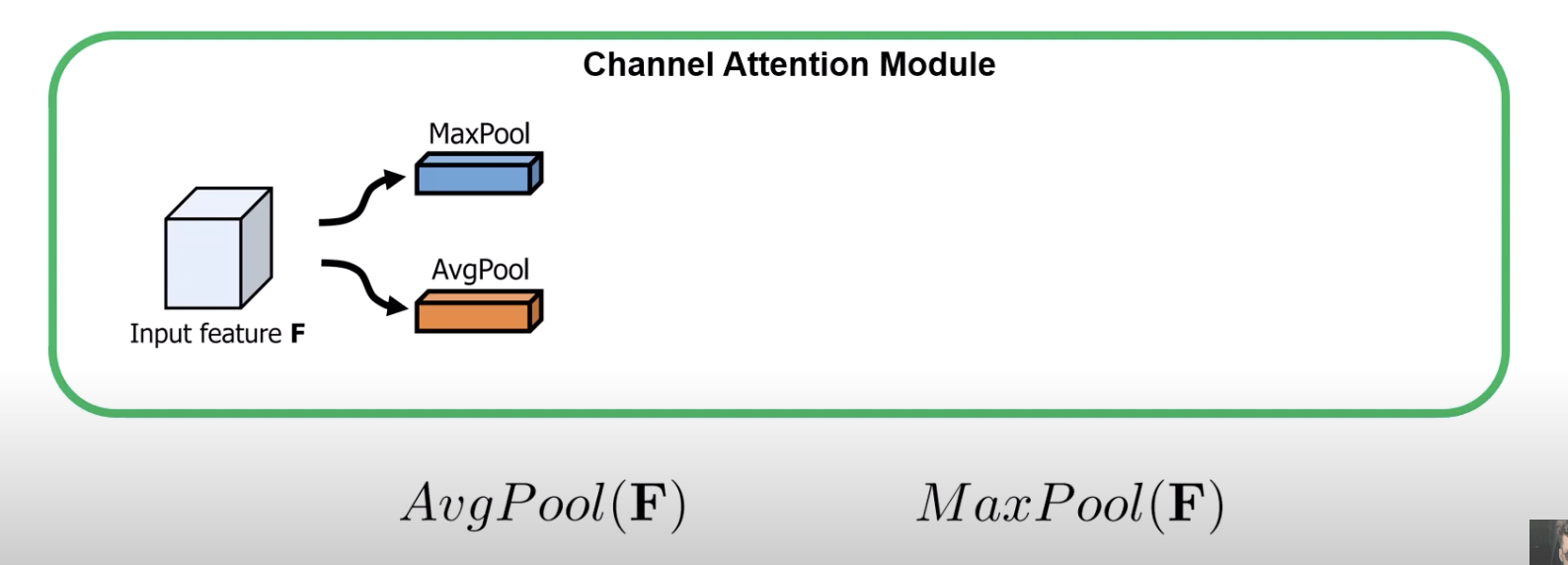
- first do avg pool and max pool to get representations of layers
- this is across the spatial dimension (so for channel Red, what is the average value)
- first do avg pool and max pool to get representations of layers
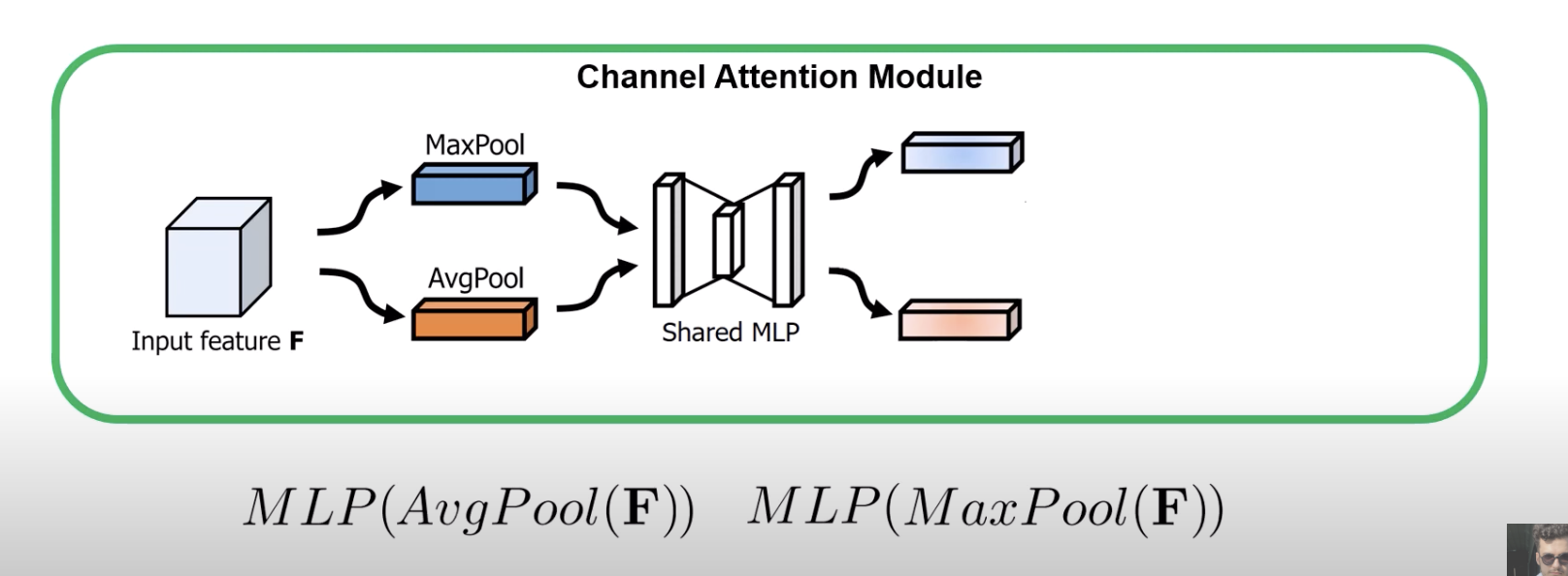
- now we pass it into a shared MLP that outputs two vectors, one for avg pool and the other for maxpool
- this shared mlp is exactly like what we had in squeeze and excite
- the image is prob misleading since it hsould be two different MLPs (since in the math formula, they are separate)
- this shared mlp is exactly like what we had in squeeze and excite
- but ultimately, we need a single value that determines which channel is more important than others, so we sum it all and use a sigmoid
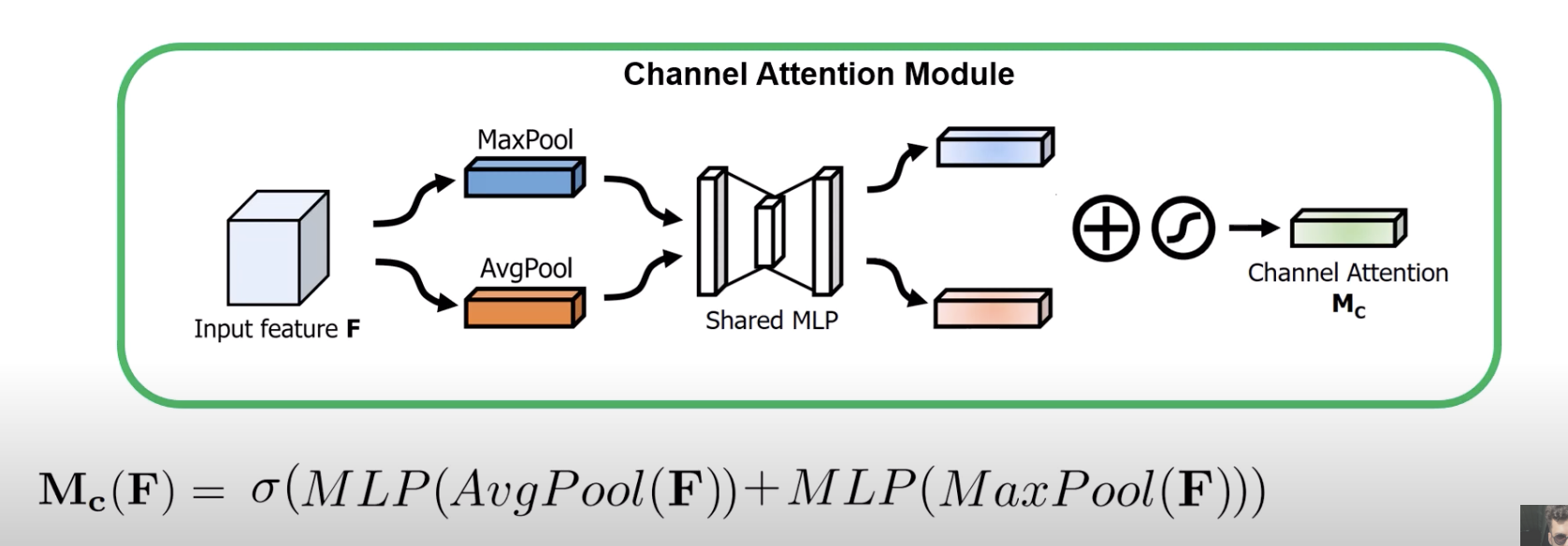
- now we pass it into a shared MLP that outputs two vectors, one for avg pool and the other for maxpool
- this feels like Squeeze-and-Excitation layer, but there’s an added maxpool (so we get more information about individual channels before the shared MLP)
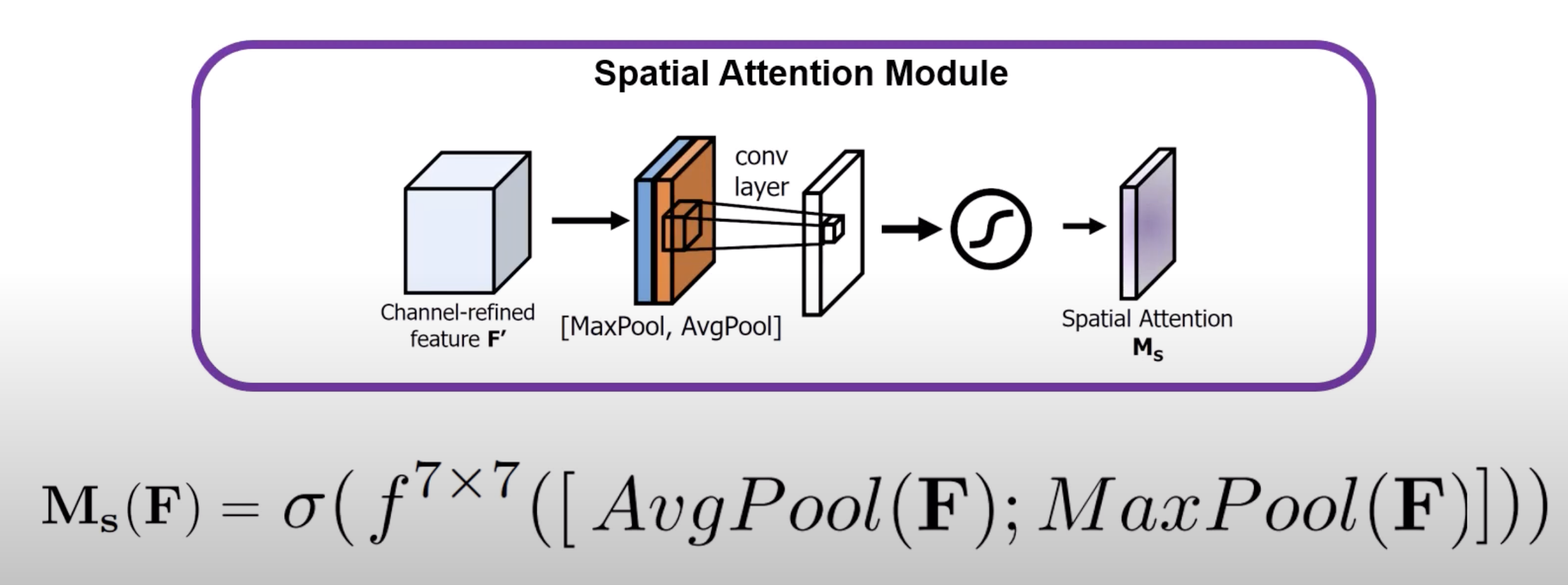
- How the spatial attention module works:
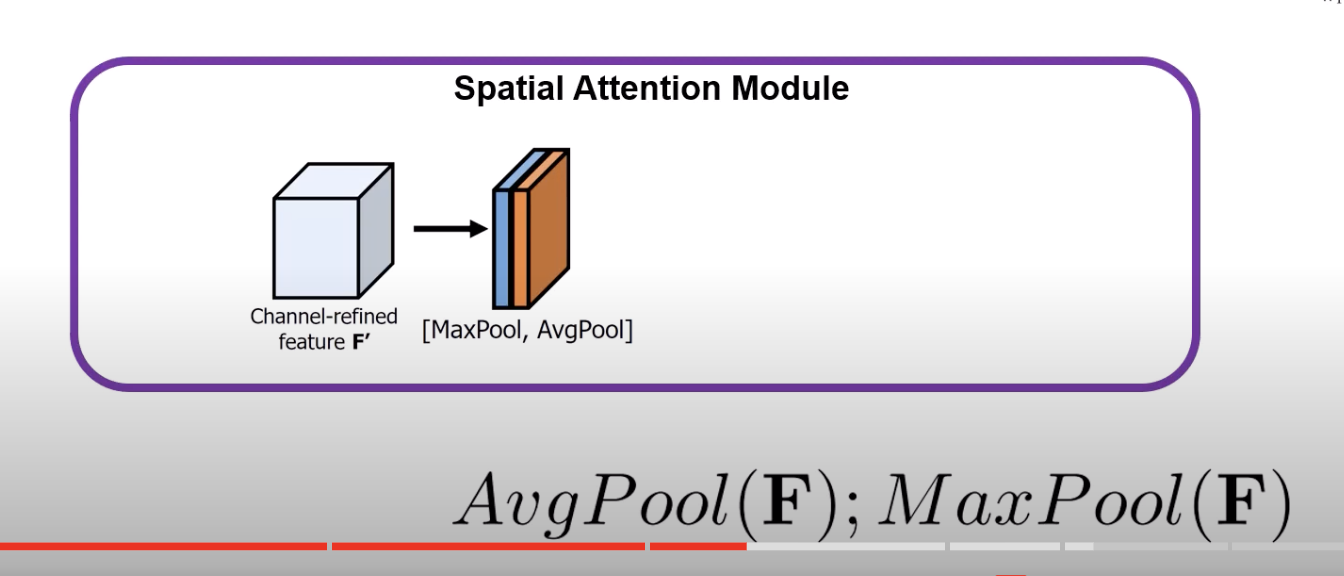
- first apply avg pool and max pool
- but unlike before, we’re doing these avg pool per pixel (across channels)
- so for each pixel vector, we AVGPool all of the channels for that individual pixel
- but unlike before, we’re doing these avg pool per pixel (across channels)
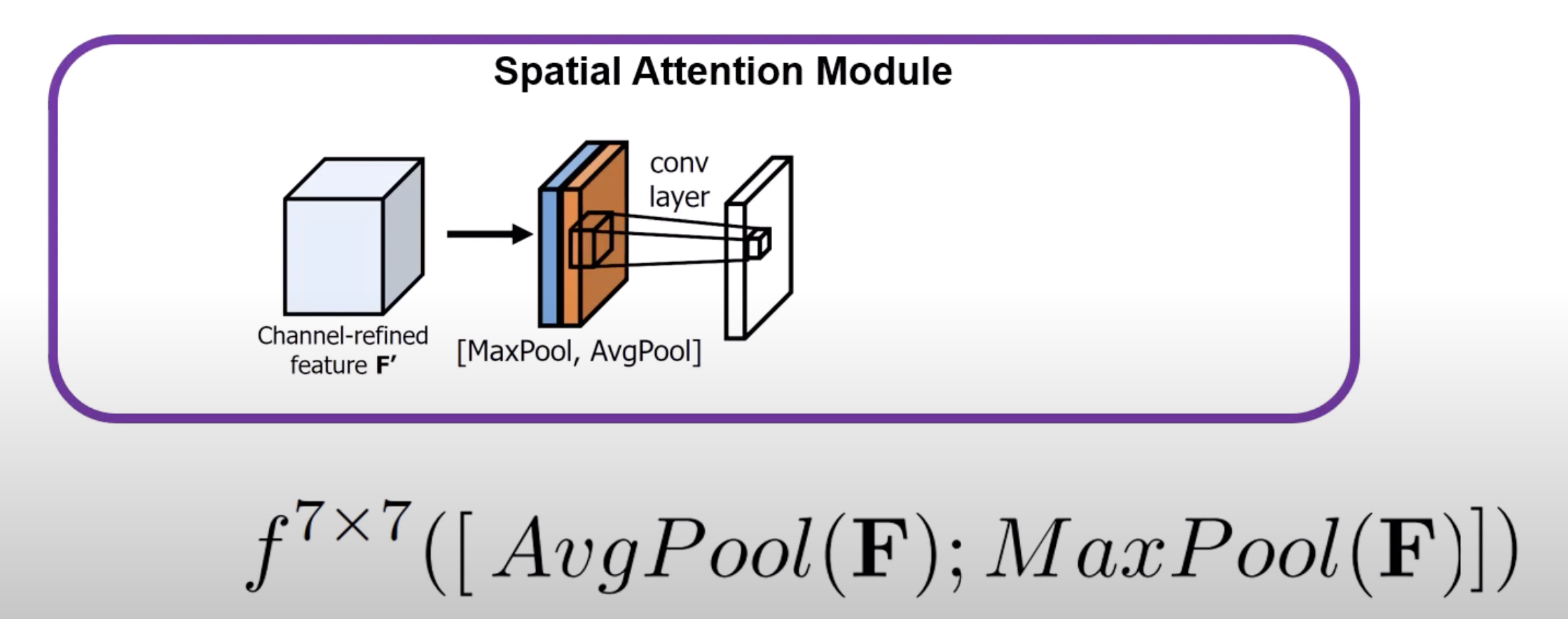
- now we concat and put it through a conv layer to learn which region is more important
- they used a 7x7 kernel cause it performed the best
- finally, just put it through a sigmoid
- We integrate these layers just like we integrate Squeeze-and-Excitation layer