- github: https://github.com/dreamquark-ai/tabnet
- https://arxiv.org/pdf/1908.07442.pdf
- how it works:
- the idea is that if you know how. a table’s features are distributed, then if you see missing data, you can infer the missing column
- this doesn’t only apply to the target column, but to other input columns as well
- This model is a seq-to-seq model. The idea is to impute the missing data.
- the encoder will create a representation of the data
- the decoder will read this representation and guess the missing data (yhat is considered missing data!)
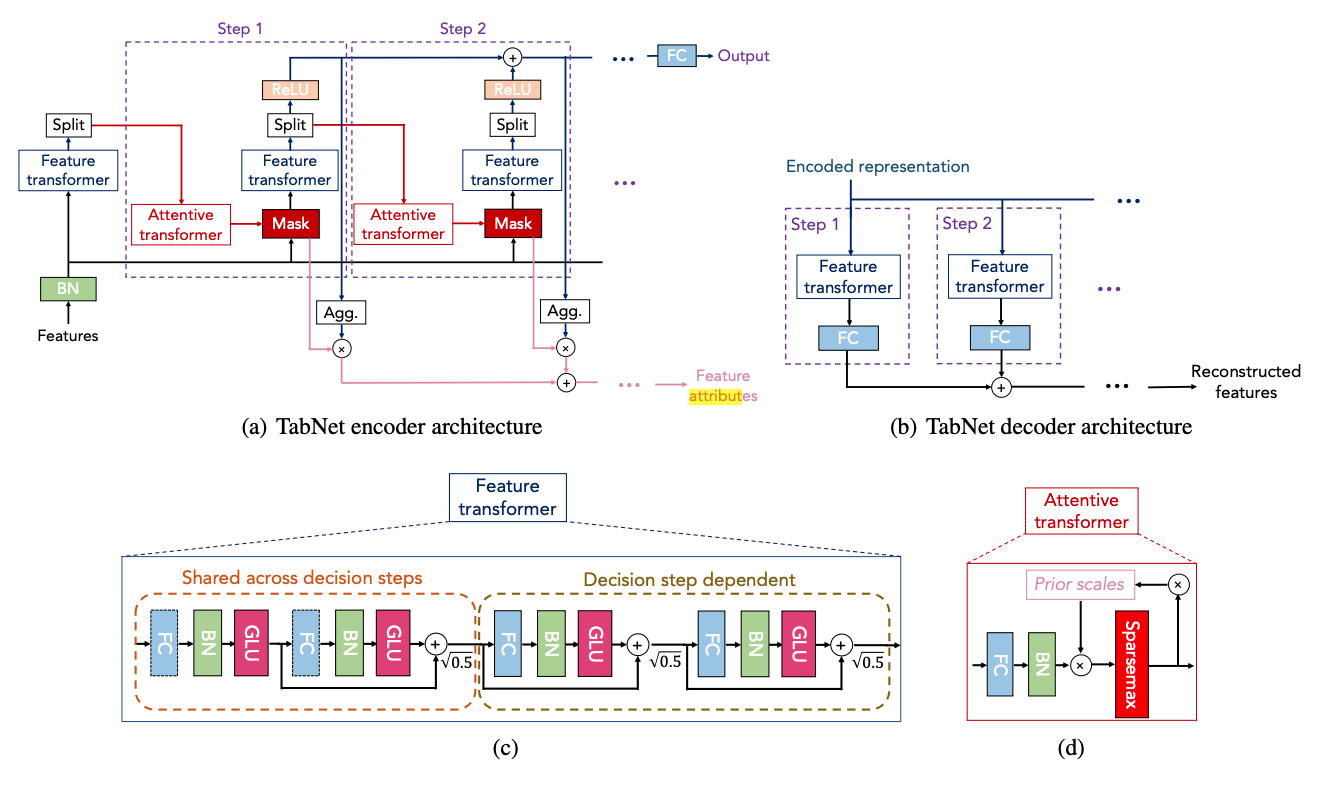
- Why does the encoder have two outputs?
- The signal at the top of the encoder is what goes into the decoder (to predict the missing data)
- the signal at the bottom (feature attributes) is used to tell us “how important feature x is”
- cause this signal is derived from the mask, which includes/excludes features based on its importance
- this signal isn’t used to calculate loss. Only the top signal is
- You can think of each step of the encoder as a branch in the decision tree that splits features
- at every split, we generate a better representation of the data (which is summed in the top signal and goes to the output)
- and each time we split, we record which features are important by adding it to the bottom signal
- Why does the encoder have two outputs?
- how it works:
“TabNet (Arik et al., 2019) proposes a sparse attention mechanism that is stacked in multiple layers to mimic the recursive splitting of decision trees”