- https://www.width.ai/post/what-is-beam-search
- an algorithm used in many NLP and speech recognition models as a final decision making layer to choose the best output
- why not just select the next token that has highest probability (greedy)
- cause this word might be good now, but as we generate the rest of the text, it might turn out to be worse than we thought
- greedy search struggle with longer outputs
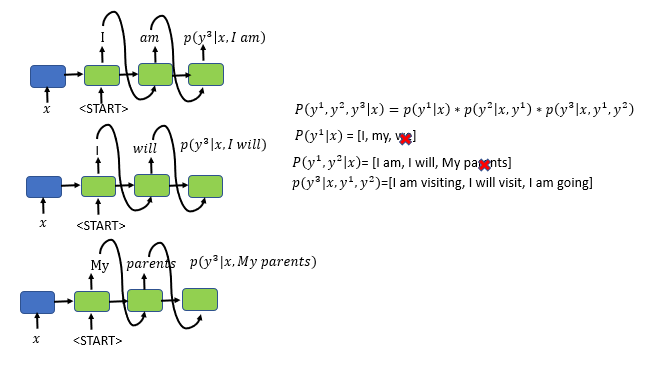
- beam search is better cause it compares multiple output generations and it chooses the best one
- https://towardsdatascience.com/an-intuitive-explanation-of-beam-search-9b1d744e7a0f
- note: since beam search is on inference time, it’s not that expensive
- notice how each time we call the decoder, we choose different words for the preceeding output tokens
- we could probably do the same for transformer outputs
- the generation will probably be like 10-50x slower since we have to make many more calls (for each token)