-
ReLU (Rectified Linear Unit): The function returns 0 if it receives any negative input, but for any positive input, it returns that value back. One of the primary benefits of using ReLU activation function is that it does not activate all the neurons at the same time. This means that the neurons will only be deactivated if the output of the linear transformation is less than 0.
Formula:
f(x) = max(0, x) -
Sigmoid: It is a smooth, differentiable function that is used to convert any real-valued number to a value between 0 and 1. It’s commonly used in the output layer of a binary classification network.
Formula:
f(x) = 1 / (1 + exp(-x)) -
Tanh (Hyperbolic Tangent): Just like the sigmoid function, tanh also normalizes the real-valued number to a range between -1 and 1. As a result, the model will converge faster towards the solution.
Formula:
f(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x)) -
Softmax: It’s often used in the output layer of a multiclass classification network. It squashes the outputs of each unit to be between 0 and 1, similar to a sigmoid function. It also divides each output such that the total sum of the outputs is equal to 1.
- softmax vs sigmoid?
- sigmoid is binary (for one class, on or off), softmax is for multiple
- softmax vs sigmoid?
-
Leaky ReLU: It is a variant of ReLU that solves the issue of dying neurons in ReLU. Instead of defining all negative inputs as 0, we define them with a small linear component.
Formula:
f(x) = 0.01 * x for x < 0, f(x) = x for x >= 0 -
ELU (Exponential Linear Unit): Similar to leaky ReLU, but it takes the exponential for negative values which allows it to take on negative values when the input is less than zero.
Formula:
f(x) = x for x >= 0, f(x) = alpha * (exp(x) - 1) for x < 0 -
Sigmoid Linear Unit (Swish) This is a newer activation function introduced by Google. It’s a variant of ReLU and was found to have better performance compared to traditional activation functions in deep networks.
Formula:
f(x) = x * sigmoid(x) -
Softplus: This activation function is a smooth approximation to the ReLU function.
Formula:
f(x) = log(1 + exp(x))- A variation of this is the integral of the softplus function (used by TeaNet)
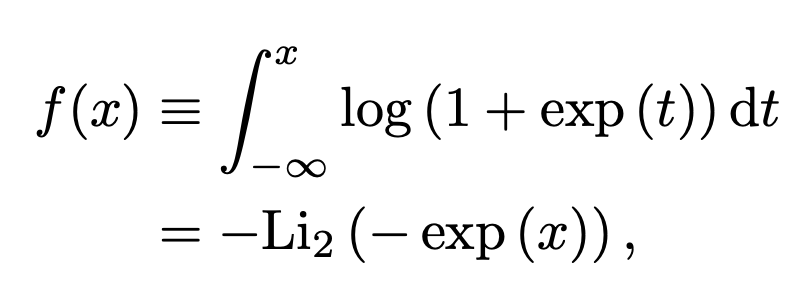 Gated Linear Units (GLU)
Gaussian Error Linear Unit (GELU)
SwiGLU
Smish
Gated Linear Units (GLU)
Gaussian Error Linear Unit (GELU)
SwiGLU
Smish